 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling the Focus of Pretrained Language Generation Models
Paper and Code

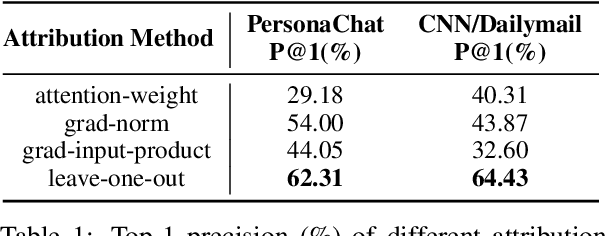
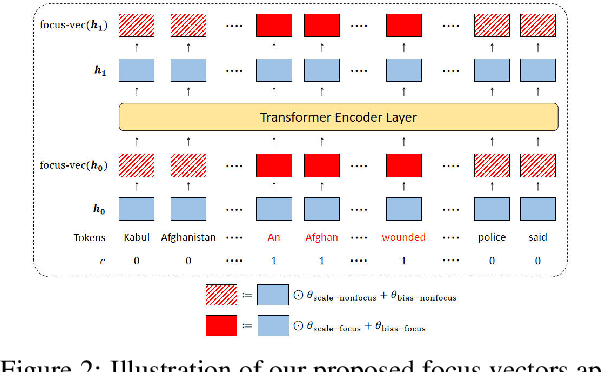
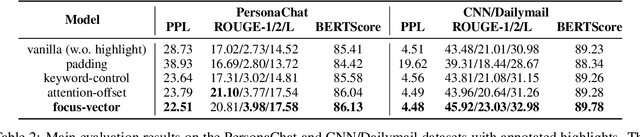
The finetuning of pretrained transformer-based language generation models are typically conducted in an end-to-end manner, where the model learns to attend to relevant parts of the input by itself. However, there does not exist a mechanism to directly control the model's focus. This work aims to develop a control mechanism by which a user can select spans of context as "highlights" for the model to focus on, and generate relevant output. To achieve this goal, we augment a pretrained model with trainable "focus vectors" that are directly applied to the model's embeddings, while the model itself is kept fixed. These vectors, trained on automatic annotations derived from attribution methods, act as indicators for context importance. We test our approach on two core generation tasks: dialogue response generation and abstractive summarization. We also collect evaluation data where the highlight-generation pairs are annotated by humans. Our experiments show that the trained focus vectors are effective in steering the model to generate outputs that are relevant to user-selected highlights.