 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled-rearing studies of newborn chicks and deep neural networks
Paper and Code
Dec 12, 2021
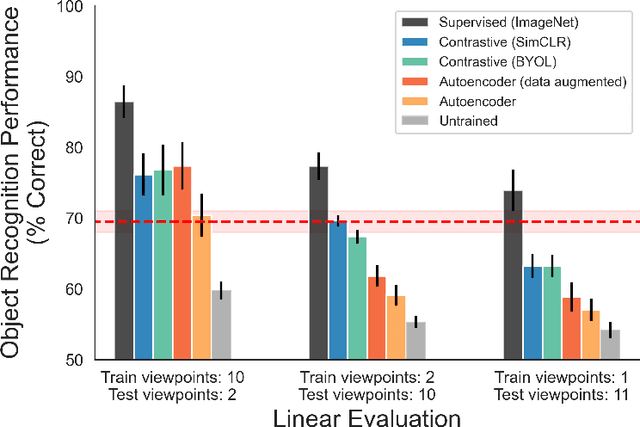
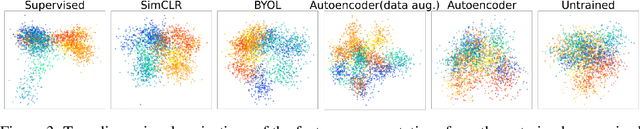
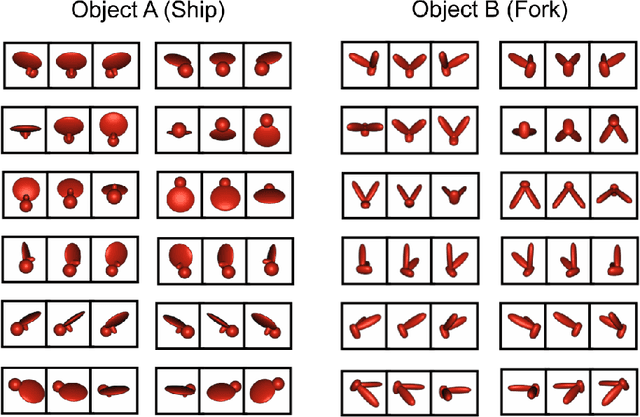
Convolutional neural networks (CNNs) can now achieve human-level performance on challenging object recognition tasks. CNNs are also the leading quantitative models in terms of predicting neural and behavioral responses in visual recognition tasks. However, there is a widely accepted critique of CNN models: unlike newborn animals, which learn rapidly and efficiently, CNNs are thought to be "data hungry," requiring massive amounts of training data to develop accurate models for object recognition. This critique challenges the promise of using CNNs as models of visual development. Here, we directly examined whether CNNs are more data hungry than newborn animals by performing parallel controlled-rearing experiments on newborn chicks and CNNs. We raised newborn chicks in strictly controlled visual environments, then simulated the training data available in that environment by constructing a virtual animal chamber in a video game engine. We recorded the visual images acquired by an agent moving through the virtual chamber and used those images to train CNNs. When CNNs received similar visual training data as chicks, the CNNs successfully solved the same challenging view-invariant object recognition tasks as the chicks. Thus, the CNNs were not more data hungry than animals: both CNNs and chicks successfully developed robust object models from training data of a single object.