 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastively Learning Visual Attention as Affordance Cues from Demonstrations for Robotic Grasping
Paper and Code
Apr 11, 2021

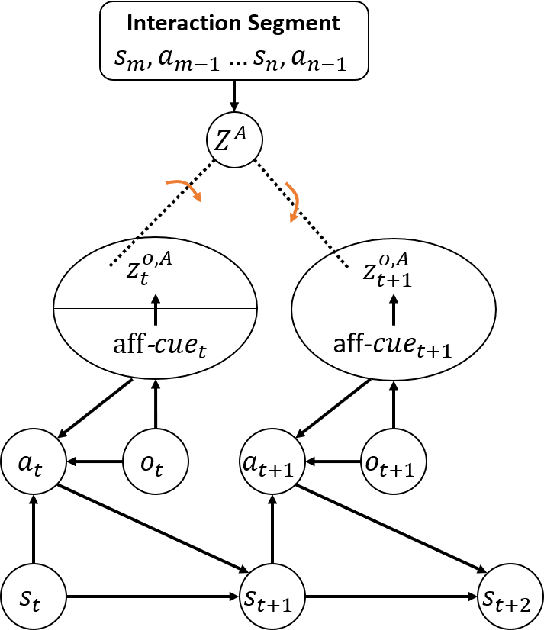
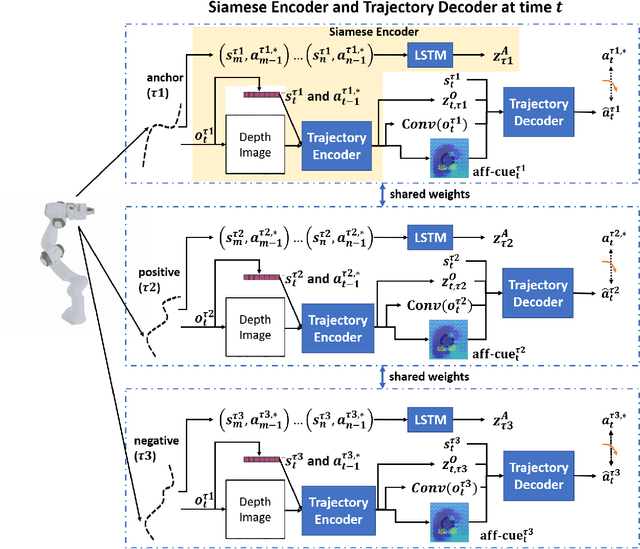
Conventional works that learn grasping affordance from demonstrations need to explicitly predict grasping configurations, such as gripper approaching angles or grasping preshapes. Classic motion planners could then sample trajectories by using such predicted configurations. In this work, our goal is instead to integrate the two objectives of affordance discovery and affordance-aware policy learning in an end-to-end imitation learning framework based on deep neural networks. From a psychological perspective, there is a close association between attention and affordance. Therefore, with an end-to-end neural network, we propose to learn affordance cues as visual attention that serves as a useful indicating signal of how a demonstrator accomplishes tasks. To achieve this, we propose a contrastive learning framework that consists of a Siamese encoder and a trajectory decoder. We further introduce a coupled triplet loss to encourage the discovered affordance cues to be more affordance-relevant. Our experimental results demonstrate that our model with the coupled triplet loss achieves the highest grasping success rate.