 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Document Representation Learning with Graph Attention Networks
Paper and Code
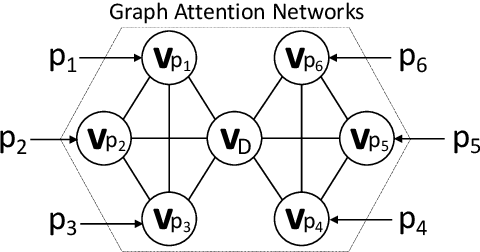
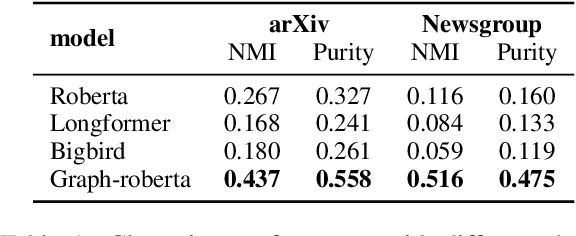
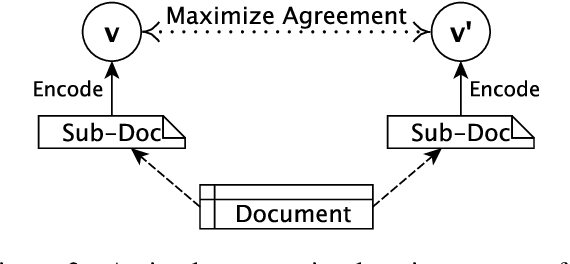
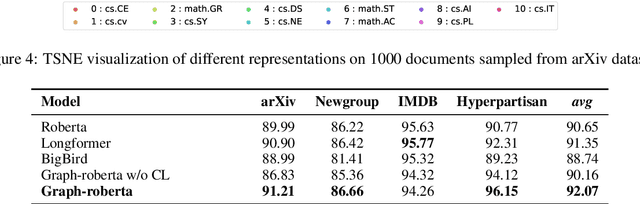
Recent progress in pretrained Transformer-based language models has shown great success in learning contextual representation of text. However, due to the quadratic self-attention complexity, most of the pretrained Transformers models can only handle relatively short text. It is still a challenge when it comes to modeling very long documents. In this work, we propose to use a graph attention network on top of the available pretrained Transformers model to learn document embeddings. This graph attention network allows us to leverage the high-level semantic structure of the document. In addition, based on our graph document model, we design a simple contrastive learning strategy to pretrain our models on a large amount of unlabeled corpus. Empirically, we demonstrate the effectiveness of our approaches in document classification and document retrieval tasks.