 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Adapters for Foundation Model Group Robustness
Paper and Code



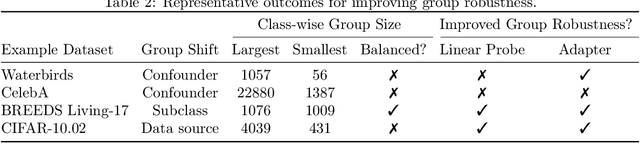
While large pretrained foundation models (FMs) have shown remarkable zero-shot classification robustness to dataset-level distribution shifts, their robustness to subpopulation or group shifts is relatively underexplored. We study this problem, and find that FMs such as CLIP may not be robust to various group shifts. Across 9 robustness benchmarks, zero-shot classification with their embeddings results in gaps of up to 80.7 percentage points (pp) between average and worst-group accuracy. Unfortunately, existing methods to improve robustness require retraining, which can be prohibitively expensive on large foundation models. We also find that efficient ways to improve model inference (e.g., via adapters, lightweight networks with FM embeddings as inputs) do not consistently improve and can sometimes hurt group robustness compared to zero-shot (e.g., increasing the accuracy gap by 50.1 pp on CelebA). We thus develop an adapter training strategy to effectively and efficiently improve FM group robustness. Our motivating observation is that while poor robustness results from groups in the same class being embedded far apart in the foundation model "embedding space," standard adapter training may not bring these points closer together. We thus propose contrastive adapting, which trains adapters with contrastive learning to bring sample embeddings close to both their ground-truth class embeddings and other sample embeddings in the same class. Across the 9 benchmarks, our approach consistently improves group robustness, raising worst-group accuracy by 8.5 to 56.0 pp over zero-shot. Our approach is also efficient, doing so without any FM finetuning and only a fixed set of frozen FM embeddings. On benchmarks such as Waterbirds and CelebA, this leads to worst-group accuracy comparable to state-of-the-art methods that retrain entire models, while only training $\leq$1% of the model parameters.