 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuum: Simple Management of Complex Continual Learning Scenarios
Paper and Code
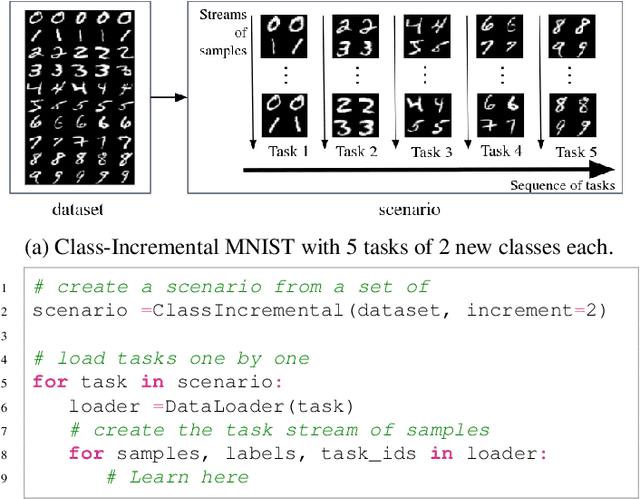

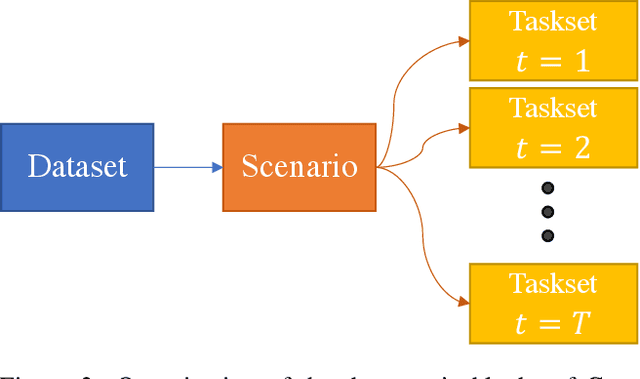

Continual learning is a machine learning sub-field specialized in settings with non-iid data. Hence, the training data distribution is not static and drifts through time. Those drifts might cause interferences in the trained model and knowledge learned on previous states of the data distribution might be forgotten. Continual learning's challenge is to create algorithms able to learn an ever-growing amount of knowledge while dealing with data distribution drifts. One implementation difficulty in these field is to create data loaders that simulate non-iid scenarios. Indeed, data loaders are a key component for continual algorithms. They should be carefully designed and reproducible. Small errors in data loaders have a critical impact on algorithm results, e.g. with bad preprocessing, wrong order of data or bad test set. Continuum is a simple and efficient framework with numerous data loaders that avoid researcher to spend time on designing data loader and eliminate time-consuming errors. Using our proposed framework, it is possible to directly focus on the model design by using the multiple scenarios and evaluation metrics implemented. Furthermore the framework is easily extendable to add novel settings for specific needs.