 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual RNN-T For Open Domain ASR
Paper and Code
Jun 04, 2020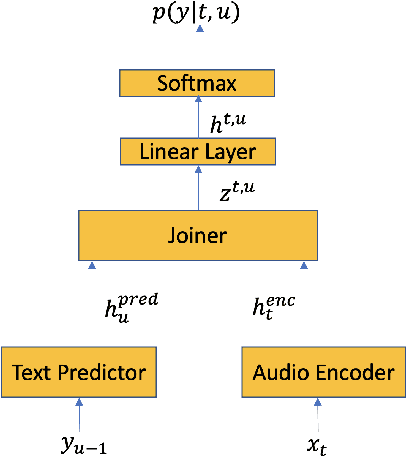



End-to-end (E2E) systems for automatic speech recognition (ASR), such as RNN Transducer (RNN-T) and Listen-Attend-Spell (LAS) blend the individual components of a traditional hybrid ASR system - acoustic model, language model, pronunciation model - into a single neural network. While this has some nice advantages, it limits the system to be trained using only paired audio and text. Because of this, E2E models tend to have difficulties with correctly recognizing rare words that are not frequently seen during training, such as entity names. In this paper, we propose modifications to the RNN-T model that allow the model to utilize additional metadata text with the objective of improving performance on these named entity words. We evaluate our approach on an in-house dataset sampled from de-identified public social media videos, which represent an open domain ASR task. By using an attention model to leverage the contextual metadata that accompanies a video, we observe a relative improvement of about 12% in Word Error Rate on Named Entities (WER-NE) for videos with related metadata.