 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Joint Factor Acoustic Embeddings
Paper and Code
Oct 16, 2019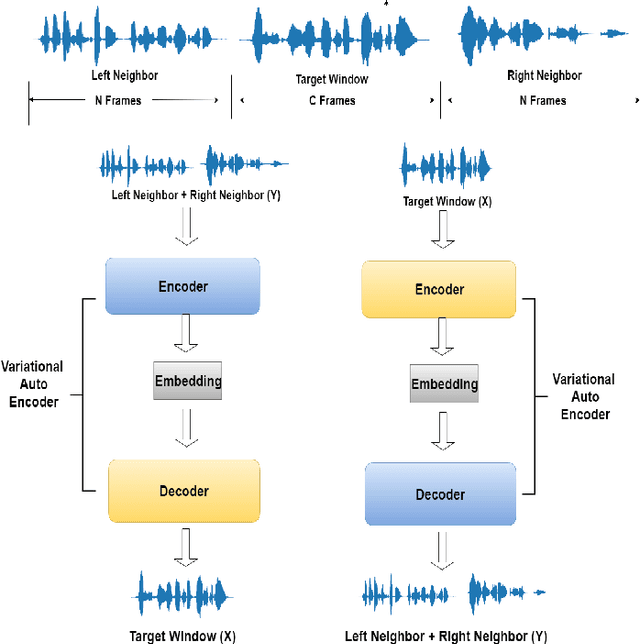
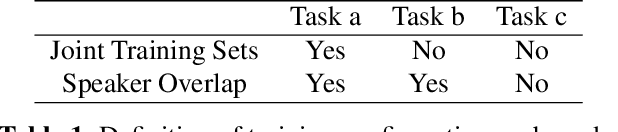
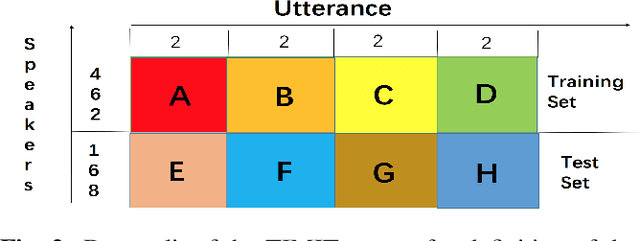
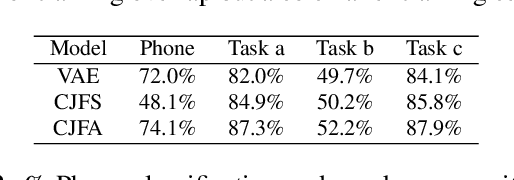
Embedding acoustic information into fixed length representations is of interest for a whole range of applications in speech and audio technology. We propose two novel unsupervised approaches to generate acoustic embeddings by modelling of acoustic context. The first approach is a contextual joint factor synthesis encoder, where the encoder in an encoder/decoder framework is trained to extract joint factors from surrounding audio frames to best generate the target output. The second approach is a contextual joint factor analysis encoder, where the encoder is trained to analyse joint factors from the source signal that correlates best with the neighbouring audio. To evaluate the effectiveness of our approaches compared to prior work, we chose two tasks - phone classification and speaker recognition - and test on different TIMIT data sets. Experimental results show that one of our proposed approaches outperforms phone classification baselines, yielding a classification accuracy of 74.1%. When using additional out-of-domain data for training, an additional 2-3% improvements can be obtained, for both for phone classification and speaker recognition tasks.