 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextformer: A Transformer with Spatio-Channel Attention for Context Modeling in Learned Image Compression
Paper and Code
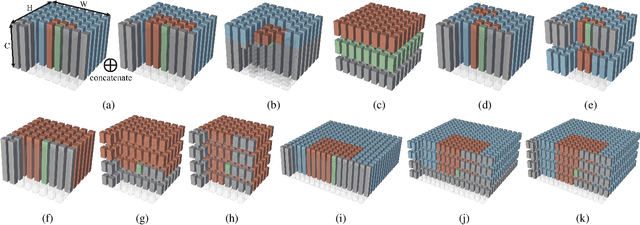

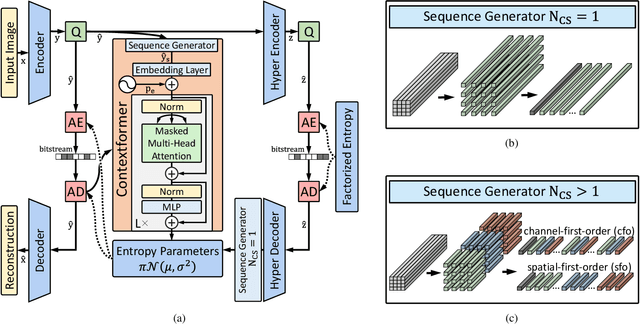
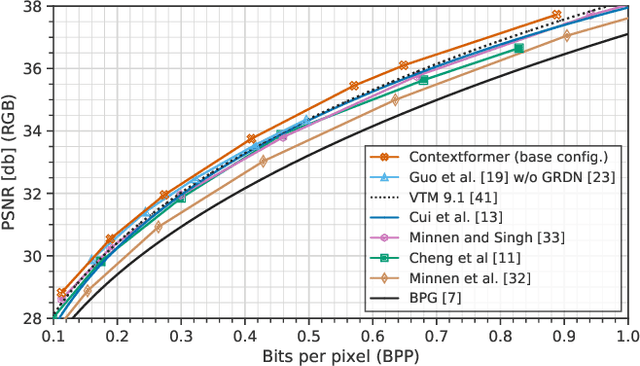
Entropy modeling is a key component for high-performance image compression algorithms. Recent developments in autoregressive context modeling helped learning-based methods to surpass their classical counterparts. However, the performance of those models can be further improved due to the underexploited spatio-channel dependencies in latent space, and the suboptimal implementation of context adaptivity. Inspired by the adaptive characteristics of the transformers, we propose a transformer-based context model, a.k.a. Contextformer, which generalizes the de facto standard attention mechanism to spatio-channel attention. We replace the context model of a modern compression framework with the Contextformer and test it on the widely used Kodak image dataset. Our experimental results show that the proposed model provides up to 10% rate savings compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 9.1, and outperforms various learning-based models.