 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Driven Data Mining through Bias Removal and Data Incompleteness Mitigation
Paper and Code
Oct 19, 2019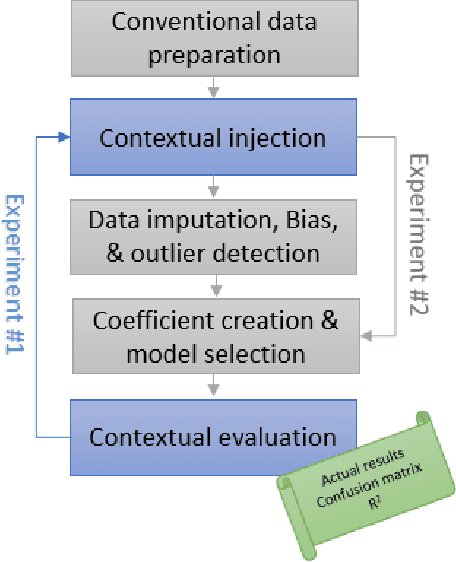
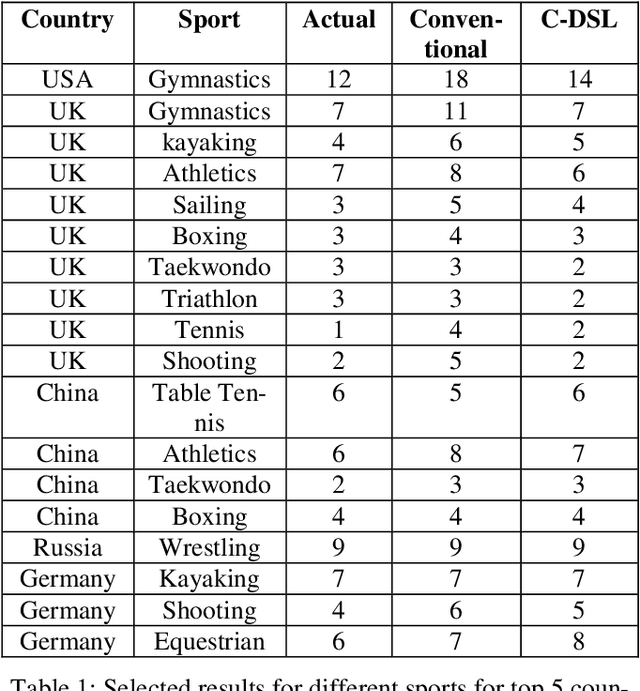

The results of data mining endeavors are majorly driven by data quality. Throughout these deployments, serious show-stopper problems are still unresolved, such as: data collection ambiguities, data imbalance, hidden biases in data, the lack of domain information, and data incompleteness. This paper is based on the premise that context can aid in mitigating these issues. In a traditional data science lifecycle, context is not considered. Context-driven Data Science Lifecycle (C-DSL); the main contribution of this paper, is developed to address these challenges. Two case studies (using data-sets from sports events) are developed to test C-DSL. Results from both case studies are evaluated using common data mining metrics such as: coefficient of determination (R2 value) and confusion matrices. The work presented in this paper aims to re-define the lifecycle and introduce tangible improvements to its outcomes.