 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Based Medical Image Retrieval with Opponent Class Adaptive Margin Loss
Paper and Code
Nov 22, 2022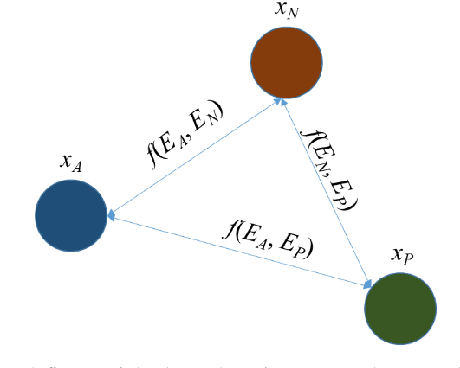
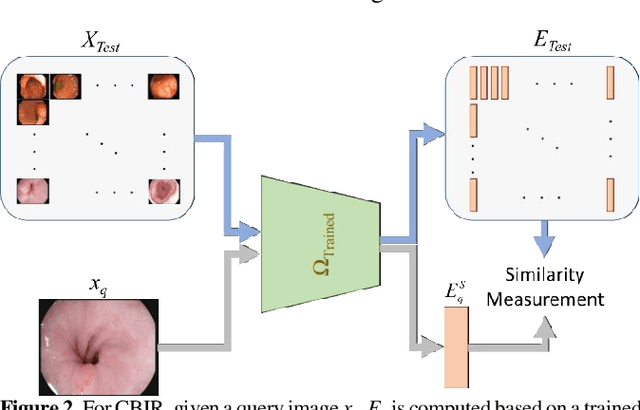
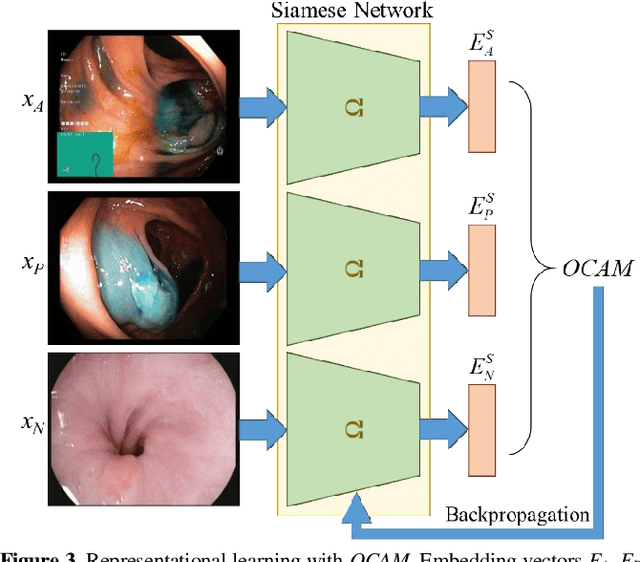
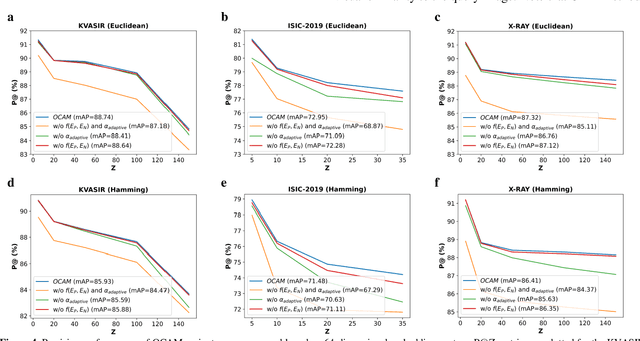
Broadspread use of medical imaging devices with digital storage has paved the way for curation of substantial data repositories. Fast access to image samples with similar appearance to suspected cases can help establish a consulting system for healthcare professionals, and improve diagnostic procedures while minimizing processing delays. However, manual querying of large data repositories is labor intensive. Content-based image retrieval (CBIR) offers an automated solution based on dense embedding vectors that represent image features to allow quantitative similarity assessments. Triplet learning has emerged as a powerful approach to recover embeddings in CBIR, albeit traditional loss functions ignore the dynamic relationship between opponent image classes. Here, we introduce a triplet-learning method for automated querying of medical image repositories based on a novel Opponent Class Adaptive Margin (OCAM) loss. OCAM uses a variable margin value that is updated continually during the course of training to maintain optimally discriminative representations. CBIR performance of OCAM is compared against state-of-the-art loss functions for representational learning on three public databases (gastrointestinal disease, skin lesion, lung disease). Comprehensive experiments in each application domain demonstrate the superior performance of OCAM against baselines.