 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Artificial Data for Fine-tuning for Low-Resource Biomedical Text Tagging with Applications in PICO Annotation
Paper and Code


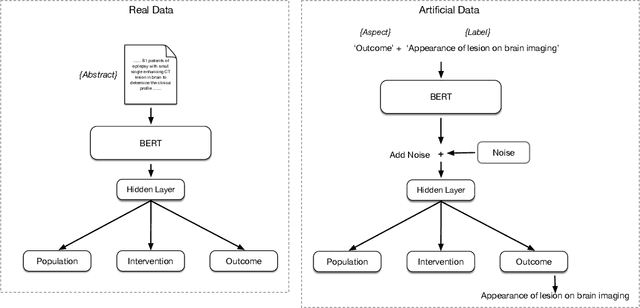

Biomedical text tagging systems are plagued by the dearth of labeled training data. There have been recent attempts at using pre-trained encoders to deal with this issue. Pre-trained encoder provides representation of the input text which is then fed to task-specific layers for classification. The entire network is fine-tuned on the labeled data from the target task. Unfortunately, a low-resource biomedical task often has too few labeled instances for satisfactory fine-tuning. Also, if the label space is large, it contains few or no labeled instances for majority of the labels. Most biomedical tagging systems treat labels as indexes, ignoring the fact that these labels are often concepts expressed in natural language e.g. `Appearance of lesion on brain imaging'. To address these issues, we propose constructing extra labeled instances using label-text (i.e. label's name) as input for the corresponding label-index (i.e. label's index). In fact, we propose a number of strategies for manufacturing multiple artificial labeled instances from a single label. The network is then fine-tuned on a combination of real and these newly constructed artificial labeled instances. We evaluate the proposed approach on an important low-resource biomedical task called \textit{PICO annotation}, which requires tagging raw text describing clinical trials with labels corresponding to different aspects of the trial i.e. PICO (Population, Intervention/Control, Outcome) characteristics of the trial. Our empirical results show that the proposed method achieves a new state-of-the-art performance for PICO annotation with very significant improvements over competitive baselines.