 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Regularization Can Improve Robustness to Label Noise
Paper and Code
Oct 04, 2021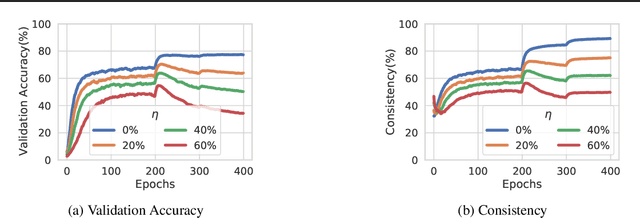
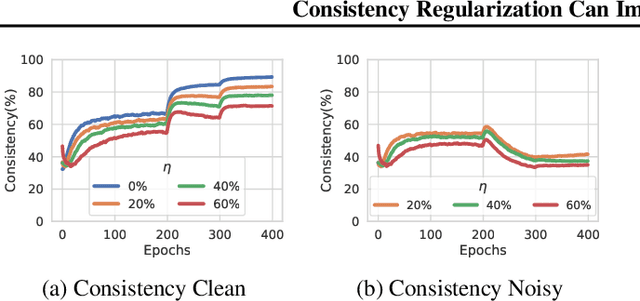
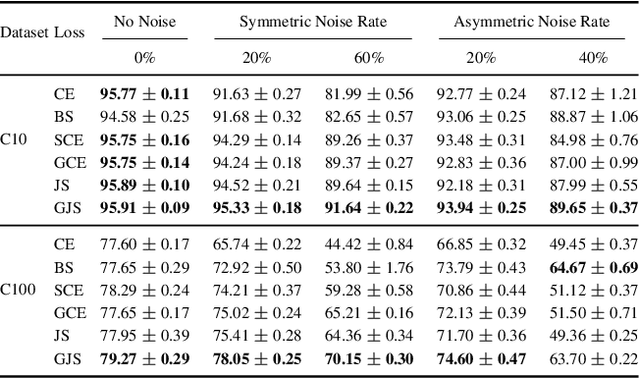
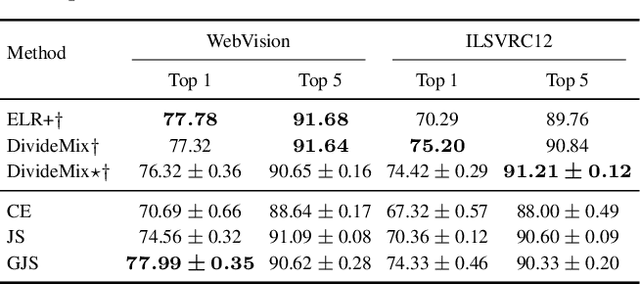
Consistency regularization is a commonly-used technique for semi-supervised and self-supervised learning. It is an auxiliary objective function that encourages the prediction of the network to be similar in the vicinity of the observed training samples. Hendrycks et al. (2020) have recently shown such regularization naturally brings test-time robustness to corrupted data and helps with calibration. This paper empirically studies the relevance of consistency regularization for training-time robustness to noisy labels. First, we make two interesting and useful observations regarding the consistency of networks trained with the standard cross entropy loss on noisy datasets which are: (i) networks trained on noisy data have lower consistency than those trained on clean data, and(ii) the consistency reduces more significantly around noisy-labelled training data points than correctly-labelled ones. Then, we show that a simple loss function that encourages consistency improves the robustness of the models to label noise on both synthetic (CIFAR-10, CIFAR-100) and real-world (WebVision) noise as well as different noise rates and types and achieves state-of-the-art results.