 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency of Neural Networks with Regularization
Paper and Code
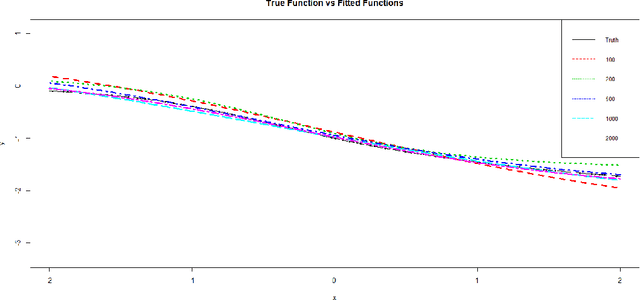
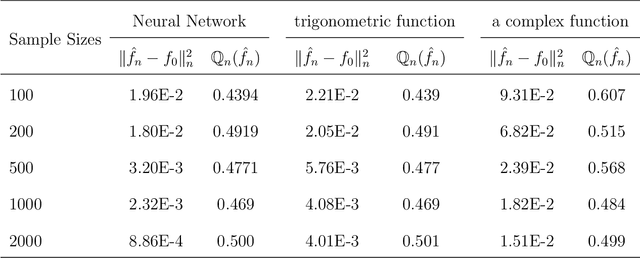
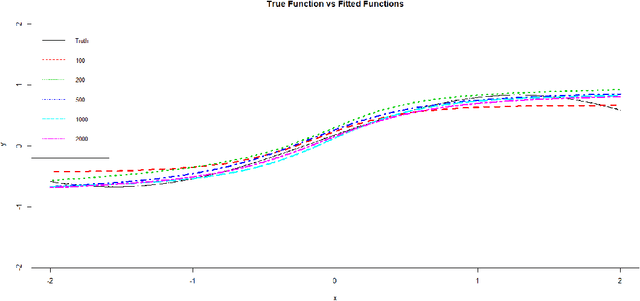
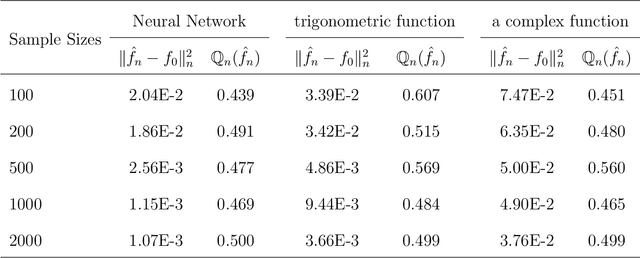
Neural networks have attracted a lot of attention due to its success in applications such as natural language processing and computer vision. For large scale data, due to the tremendous number of parameters in neural networks, overfitting is an issue in training neural networks. To avoid overfitting, one common approach is to penalize the parameters especially the weights in neural networks. Although neural networks has demonstrated its advantages in many applications, the theoretical foundation of penalized neural networks has not been well-established. Our goal of this paper is to propose the general framework of neural networks with regularization and prove its consistency. Under certain conditions, the estimated neural network will converge to true underlying function as the sample size increases. The method of sieves and the theory on minimal neural networks are used to overcome the issue of unidentifiability for the parameters. Two types of activation functions: hyperbolic tangent function(Tanh) and rectified linear unit(ReLU) have been taken into consideration. Simulations have been conducted to verify the validation of theorem of consistency.