 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Guided Scene Flow Estimation
Paper and Code
Jun 19, 2020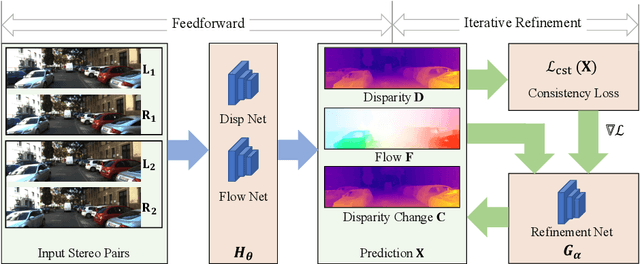



We present Consistency Guided Scene Flow Estimation (CGSF), a framework for joint estimation of 3D scene structure and motion from stereo videos. The model takes two temporal stereo pairs as input, and predicts disparity and scene flow. The model self-adapts at test time by iteratively refining its predictions. The refinement process is guided by a consistency loss, which combines stereo and temporal photo-consistency with a geometric term that couples the disparity and 3D motion. To handle the noise in the consistency loss, we further propose a learned, output refinement network, which takes the initial predictions, the loss, and the gradient as input, and efficiently predicts a correlated output update. We demonstrate with extensive experiments that the proposed model can reliably predict disparity and scene flow in many challenging scenarios, and achieves better generalization than the state-of-the-arts.