 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence sequences for sampling without replacement
Paper and Code
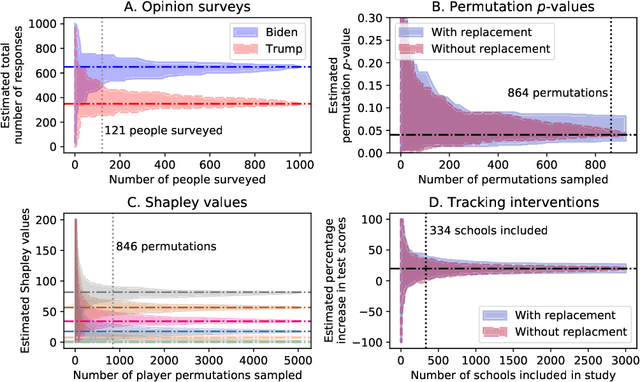
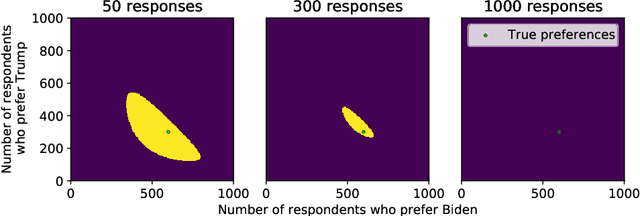
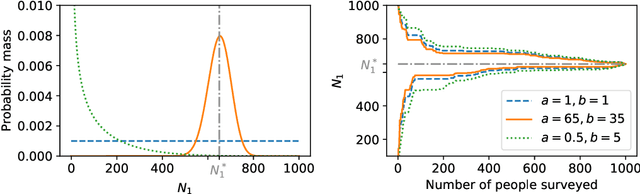
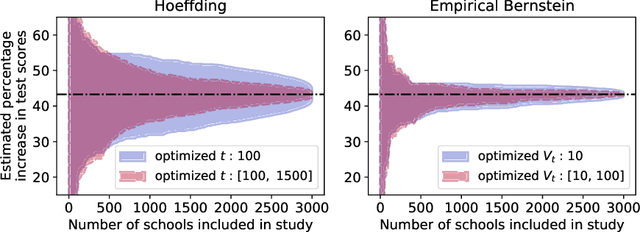
Many practical tasks involve sampling sequentially without replacement from a finite population of size $N$, in an attempt to estimate some parameter $\theta^\star$. Accurately quantifying uncertainty throughout this process is a nontrivial task, but is necessary because it often determines when we stop collecting samples and confidently report a result. We present a suite of tools to design confidence sequences (CS) for $\theta^\star$. A CS is a sequence of confidence sets $(C_n)_{n=1}^N$, that shrink in size, and all contain $\theta^\star$ simultaneously with high probability. We demonstrate their empirical performance using four example applications: local opinion surveys, calculating permutation $p$-values, estimating Shapley values, and tracking the effect of an intervention. We highlight two marked advantages over naive with-replacement sampling and/or uncertainty estimates: (1) each member of the finite population need only be queried once, saving time and money, and (2) our confidence sets are tighter and shrink to exactly zero width in $N$ steps.