 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning of Random Feature Matrices: Double Descent and Generalization Error
Paper and Code
Nov 04, 2021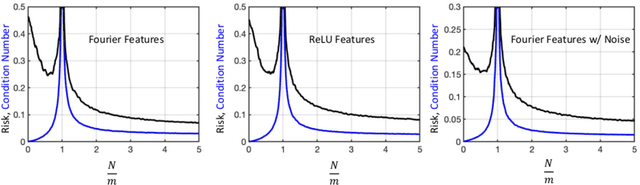
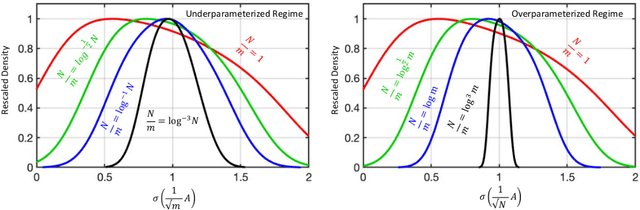
We provide (high probability) bounds on the condition number of random feature matrices. In particular, we show that if the complexity ratio $\frac{N}{m}$ where $N$ is the number of neurons and $m$ is the number of data samples scales like $\log^{-1}(N)$ or $\log(m)$, then the random feature matrix is well-conditioned. This result holds without the need of regularization and relies on establishing various concentration bounds between dependent components of the random feature matrix. Additionally, we derive bounds on the restricted isometry constant of the random feature matrix. We prove that the risk associated with regression problems using a random feature matrix exhibits the double descent phenomenon and that this is an effect of the double descent behavior of the condition number. The risk bounds include the underparameterized setting using the least squares problem and the overparameterized setting where using either the minimum norm interpolation problem or a sparse regression problem. For the least squares or sparse regression cases, we show that the risk decreases as $m$ and $N$ increase, even in the presence of bounded or random noise. The risk bound matches the optimal scaling in the literature and the constants in our results are explicit and independent of the dimension of the data.