 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Visualization: Explaining the CLIP Multi-modal Embedding Using WordNet
Paper and Code


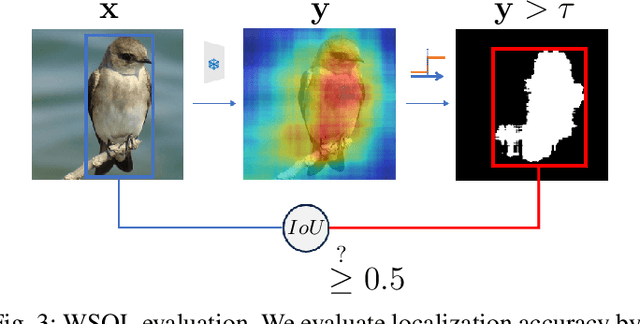

Advances in multi-modal embeddings, and in particular CLIP, have recently driven several breakthroughs in Computer Vision (CV). CLIP has shown impressive performance on a variety of tasks, yet, its inherently opaque architecture may hinder the application of models employing CLIP as backbone, especially in fields where trust and model explainability are imperative, such as in the medical domain. Current explanation methodologies for CV models rely on Saliency Maps computed through gradient analysis or input perturbation. However, these Saliency Maps can only be computed to explain classes relevant to the end task, often smaller in scope than the backbone training classes. In the context of models implementing CLIP as their vision backbone, a substantial portion of the information embedded within the learned representations is thus left unexplained. In this work, we propose Concept Visualization (ConVis), a novel saliency methodology that explains the CLIP embedding of an image by exploiting the multi-modal nature of the embeddings. ConVis makes use of lexical information from WordNet to compute task-agnostic Saliency Maps for any concept, not limited to concepts the end model was trained on. We validate our use of WordNet via an out of distribution detection experiment, and test ConVis on an object localization benchmark, showing that Concept Visualizations correctly identify and localize the image's semantic content. Additionally, we perform a user study demonstrating that our methodology can give users insight on the model's functioning.