 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Modeling with Superwords
Paper and Code
Apr 11, 2012
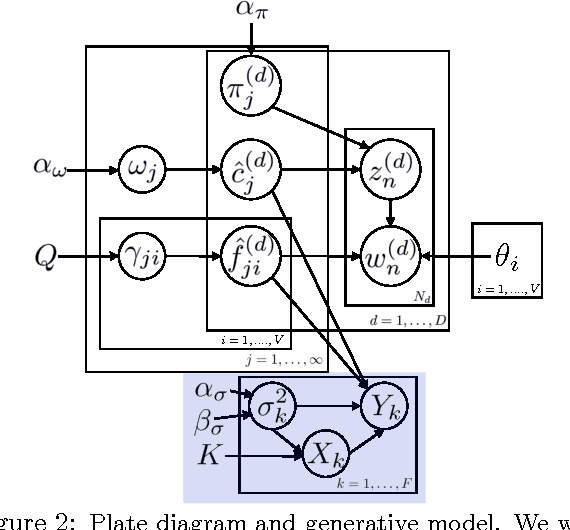
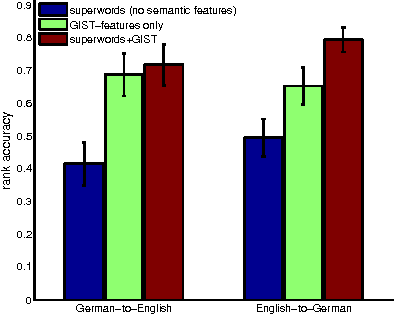

In information retrieval, a fundamental goal is to transform a document into concepts that are representative of its content. The term "representative" is in itself challenging to define, and various tasks require different granularities of concepts. In this paper, we aim to model concepts that are sparse over the vocabulary, and that flexibly adapt their content based on other relevant semantic information such as textual structure or associated image features. We explore a Bayesian nonparametric model based on nested beta processes that allows for inferring an unknown number of strictly sparse concepts. The resulting model provides an inherently different representation of concepts than a standard LDA (or HDP) based topic model, and allows for direct incorporation of semantic features. We demonstrate the utility of this representation on multilingual blog data and the Congressional Record.