 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComunication-Efficient Algorithms for Statistical Optimization
Paper and Code
Oct 11, 2013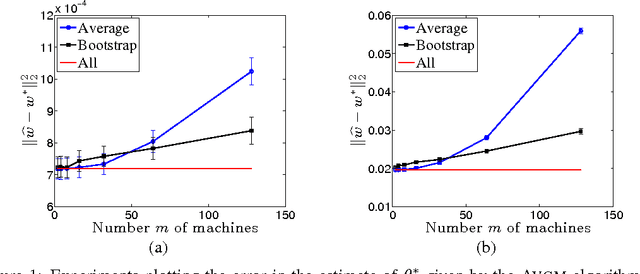
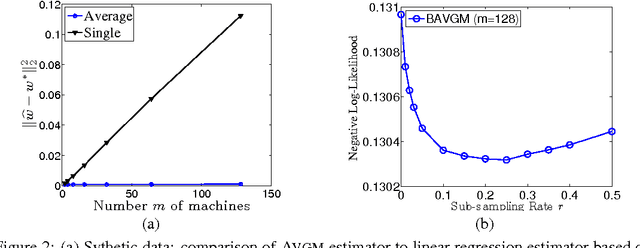
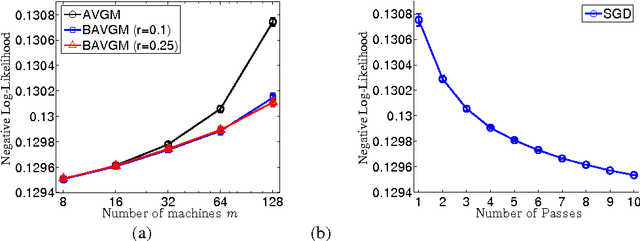
We analyze two communication-efficient algorithms for distributed statistical optimization on large-scale data sets. The first algorithm is a standard averaging method that distributes the $N$ data samples evenly to $\nummac$ machines, performs separate minimization on each subset, and then averages the estimates. We provide a sharp analysis of this average mixture algorithm, showing that under a reasonable set of conditions, the combined parameter achieves mean-squared error that decays as $\order(N^{-1}+(N/m)^{-2})$. Whenever $m \le \sqrt{N}$, this guarantee matches the best possible rate achievable by a centralized algorithm having access to all $\totalnumobs$ samples. The second algorithm is a novel method, based on an appropriate form of bootstrap subsampling. Requiring only a single round of communication, it has mean-squared error that decays as $\order(N^{-1} + (N/m)^{-3})$, and so is more robust to the amount of parallelization. In addition, we show that a stochastic gradient-based method attains mean-squared error decaying as $O(N^{-1} + (N/ m)^{-3/2})$, easing computation at the expense of penalties in the rate of convergence. We also provide experimental evaluation of our methods, investigating their performance both on simulated data and on a large-scale regression problem from the internet search domain. In particular, we show that our methods can be used to efficiently solve an advertisement prediction problem from the Chinese SoSo Search Engine, which involves logistic regression with $N \approx 2.4 \times 10^8$ samples and $d \approx 740,000$ covariates.