 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Sarcasm Analysis on Social Media: A Systematic Review
Paper and Code


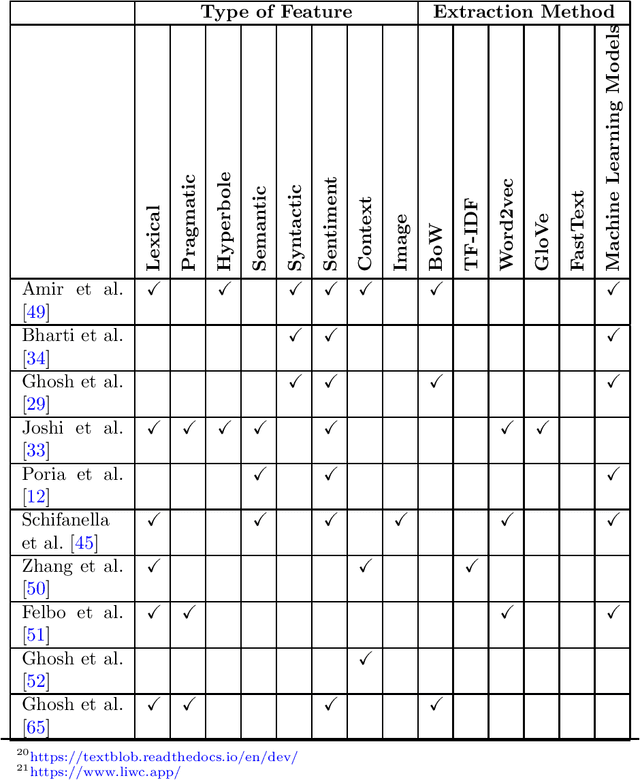
Sarcasm can be defined as saying or writing the opposite of what one truly wants to express, usually to insult, irritate, or amuse someone. Because of the obscure nature of sarcasm in textual data, detecting it is difficult and of great interest to the sentiment analysis research community. Though the research in sarcasm detection spans more than a decade, some significant advancements have been made recently, including employing unsupervised pre-trained transformers in multimodal environments and integrating context to identify sarcasm. In this study, we aim to provide a brief overview of recent advancements and trends in computational sarcasm research for the English language. We describe relevant datasets, methodologies, trends, issues, challenges, and tasks relating to sarcasm that are beyond detection. Our study provides well-summarized tables of sarcasm datasets, sarcastic features and their extraction methods, and performance analysis of various approaches which can help researchers in related domains understand current state-of-the-art practices in sarcasm detection.