 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression phase is not necessary for generalization in representation learning
Paper and Code
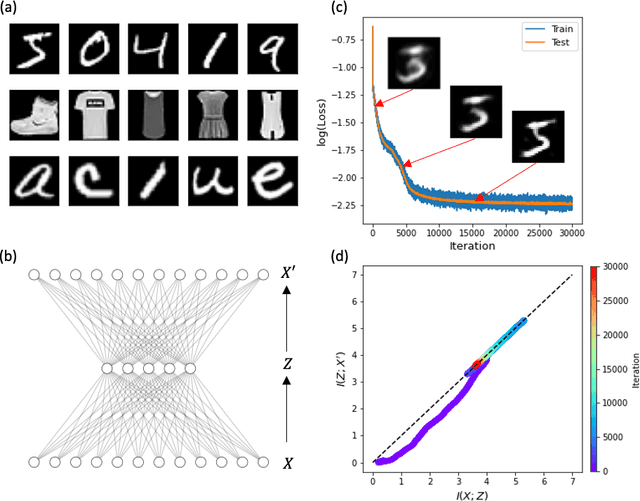
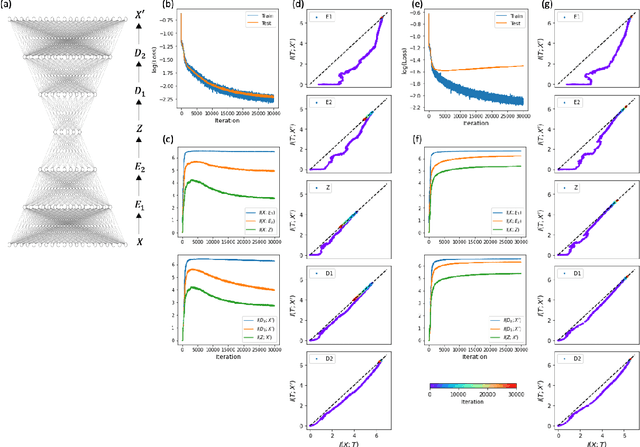
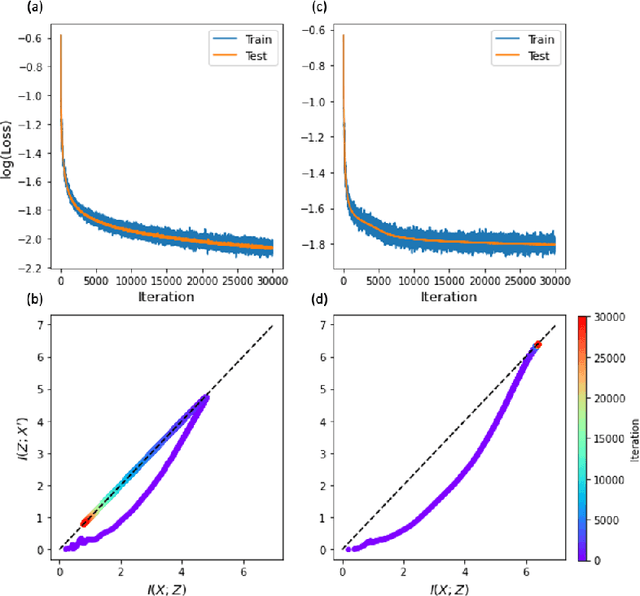
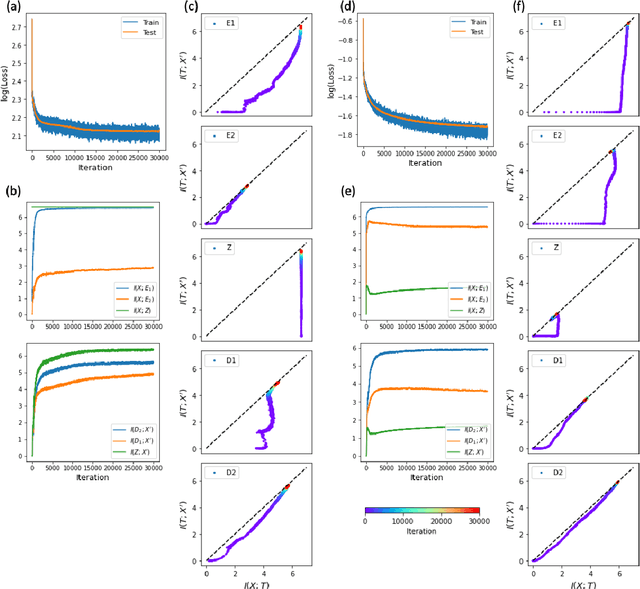
The outstanding performance of deep learning in various fields has been a fundamental query, which can be potentially examined using information theory that interprets the learning process as the transmission and compression of information. Information plane analyses of the mutual information between the input-hidden-output layers demonstrated two distinct learning phases of fitting and compression. It is debatable if the compression phase is necessary to generalize the input-output relations extracted from training data. In this study, we investigated this through experiments with various species of autoencoders and evaluated their information processing phase with an accurate kernel-based estimator of mutual information. Given sufficient training data, vanilla autoencoders demonstrated the compression phase, which was amplified after imposing sparsity regularization for hidden activities. However, we found that the compression phase is not universally observed in different species of autoencoders, including variational autoencoders, that have special constraints on network weights or manifold of hidden space. These types of autoencoders exhibited perfect generalization ability for test data without requiring the compression phase. Thus, we conclude that the compression phase is not necessary for generalization in representation learning.