 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed and distributed least-squares regression: convergence rates with applications to Federated Learning
Paper and Code
Aug 02, 2023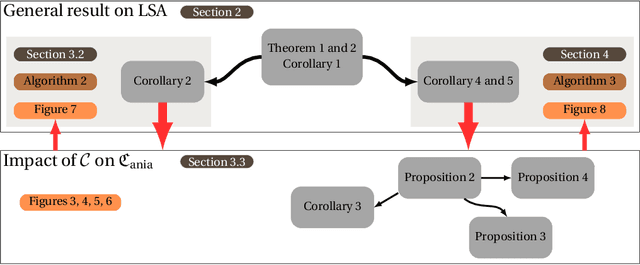
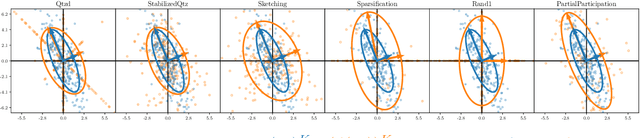
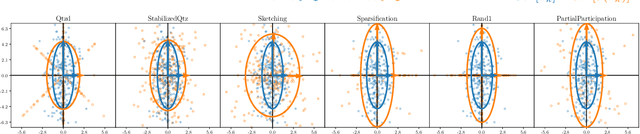
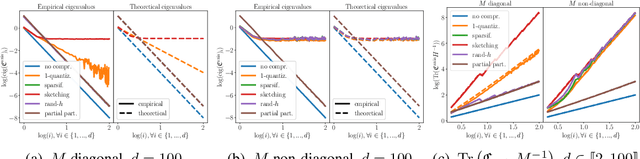
In this paper, we investigate the impact of compression on stochastic gradient algorithms for machine learning, a technique widely used in distributed and federated learning. We underline differences in terms of convergence rates between several unbiased compression operators, that all satisfy the same condition on their variance, thus going beyond the classical worst-case analysis. To do so, we focus on the case of least-squares regression (LSR) and analyze a general stochastic approximation algorithm for minimizing quadratic functions relying on a random field. We consider weak assumptions on the random field, tailored to the analysis (specifically, expected H\"older regularity), and on the noise covariance, enabling the analysis of various randomizing mechanisms, including compression. We then extend our results to the case of federated learning. More formally, we highlight the impact on the convergence of the covariance $\mathfrak{C}_{\mathrm{ania}}$ of the additive noise induced by the algorithm. We demonstrate despite the non-regularity of the stochastic field, that the limit variance term scales with $\mathrm{Tr}(\mathfrak{C}_{\mathrm{ania}} H^{-1})/K$ (where $H$ is the Hessian of the optimization problem and $K$ the number of iterations) generalizing the rate for the vanilla LSR case where it is $\sigma^2 \mathrm{Tr}(H H^{-1}) / K = \sigma^2 d / K$ (Bach and Moulines, 2013). Then, we analyze the dependency of $\mathfrak{C}_{\mathrm{ania}}$ on the compression strategy and ultimately its impact on convergence, first in the centralized case, then in two heterogeneous FL frameworks.