 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositionality as Lexical Symmetry
Paper and Code
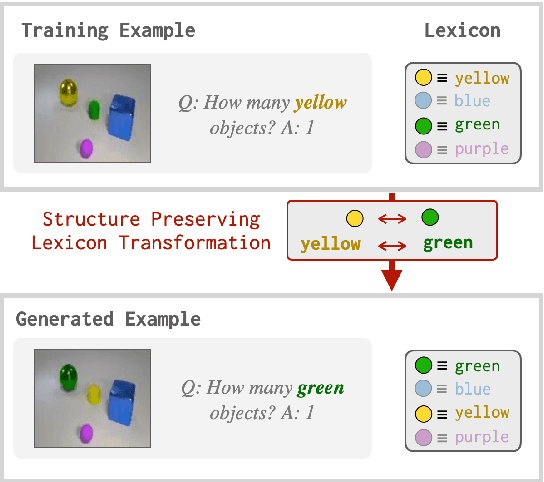
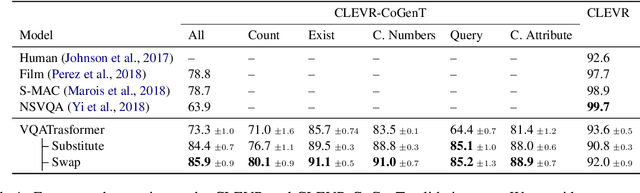
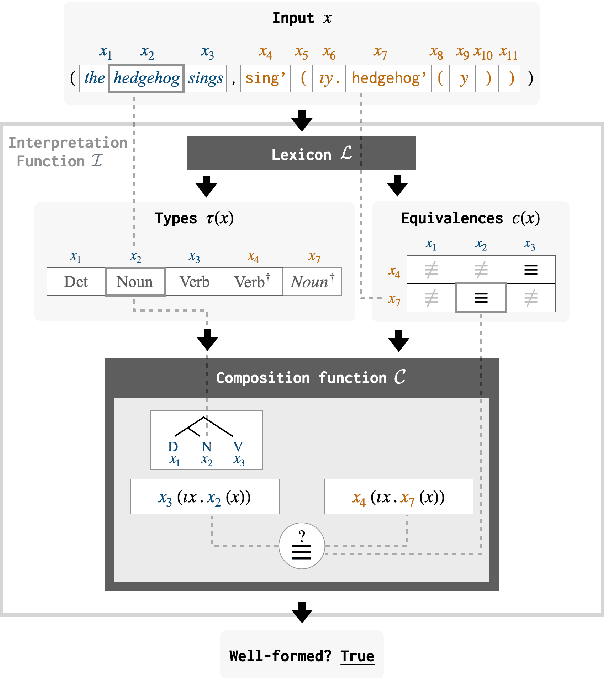

Standard deep network models lack the inductive biases needed to generalize compositionally in tasks like semantic parsing, translation, and question answering. A large body of work in natural language processing seeks to overcome this limitation with new model architectures that enforce a compositional process of sentence interpretation. In this paper, we present a domain-general framework for compositional modeling that instead formulates compositionality as a constraint on data distributions. We prove that for any task factorizable into a lexicon and a composition function, there exists a family of data transformation functions that are guaranteed to produce new, well-formed examples when applied to training data. We further show that it is possible to identify these data transformations even when the composition function is unknown (e.g. when we do not know how to write or infer a symbolic grammar). Using these transformation functions to perform data augmentation for ordinary RNN and transformer sequence models, we obtain state-of-the-art results on the CLEVR-CoGenT visual question answering dataset, and results comparable to specialized model architectures on the COGS semantic parsing dataset.