 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity Measures for Multi-objective Symbolic Regression
Paper and Code
Sep 01, 2021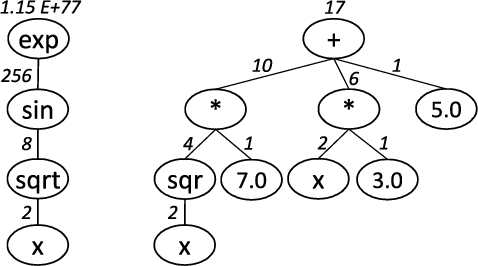
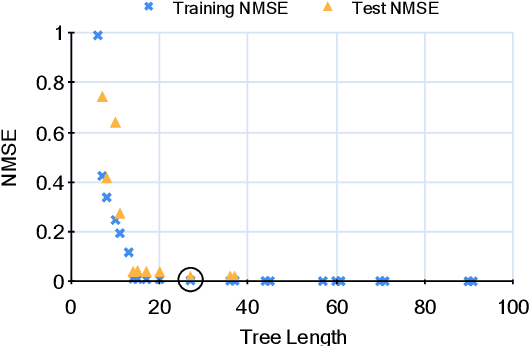
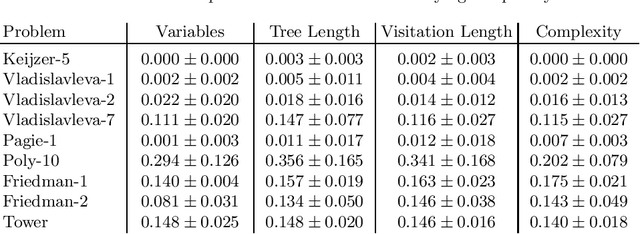
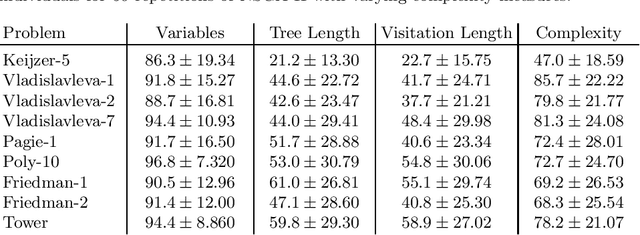
Multi-objective symbolic regression has the advantage that while the accuracy of the learned models is maximized, the complexity is automatically adapted and need not be specified a-priori. The result of the optimization is not a single solution anymore, but a whole Pareto-front describing the trade-off between accuracy and complexity. In this contribution we study which complexity measures are most appropriately used in symbolic regression when performing multi- objective optimization with NSGA-II. Furthermore, we present a novel complexity measure that includes semantic information based on the function symbols occurring in the models and test its effects on several benchmark datasets. Results comparing multiple complexity measures are presented in terms of the achieved accuracy and model length to illustrate how the search direction of the algorithm is affected.