 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete stability analysis of a heuristic ADP control design
Paper and Code
Jul 28, 2015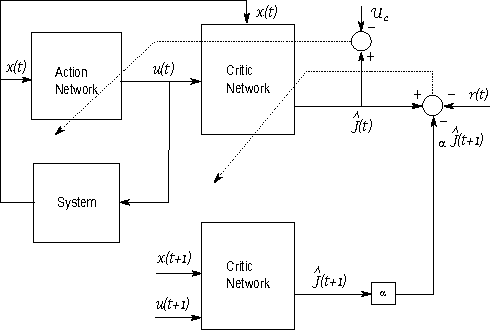
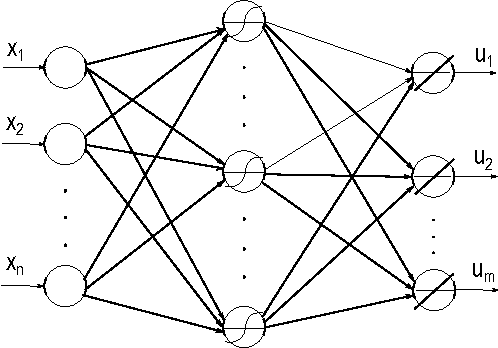
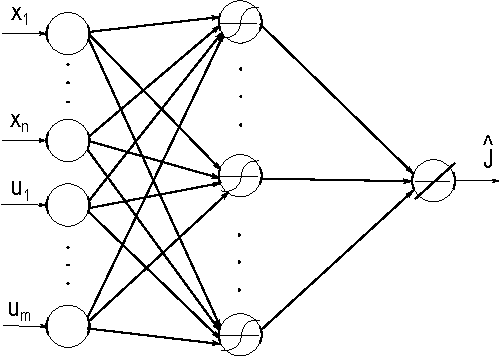
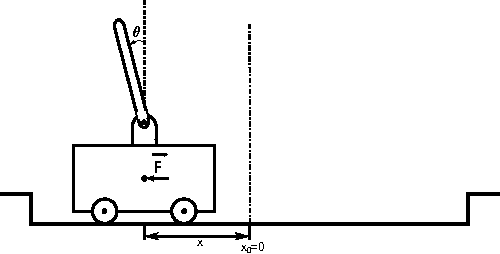
This paper provides new stability results for Action-Dependent Heuristic Dynamic Programming (ADHDP), using a control algorithm that iteratively improves an internal model of the external world in the autonomous system based on its continuous interaction with the environment. We extend previous results by ADHDP control to the case of general multi-layer neural networks with deep learning across all layers. In particular, we show that the introduced control approach is uniformly ultimately bounded (UUB) under specific conditions on the learning rates, without explicit constraints on the temporal discount factor. We demonstrate the benefit of our results to the control of linear and nonlinear systems, including the cart-pole balancing problem. Our results show significantly improved learning and control performance as compared to the state-of-art.