 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of the Deep-Learning-Based Automated Segmentation Methods for the Head Sectioned Images of the Virtual Korean Human Project
Paper and Code

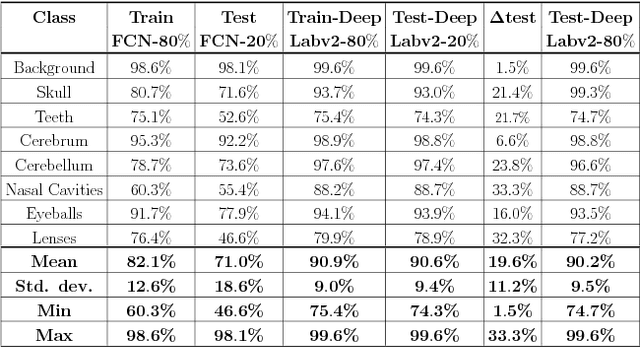
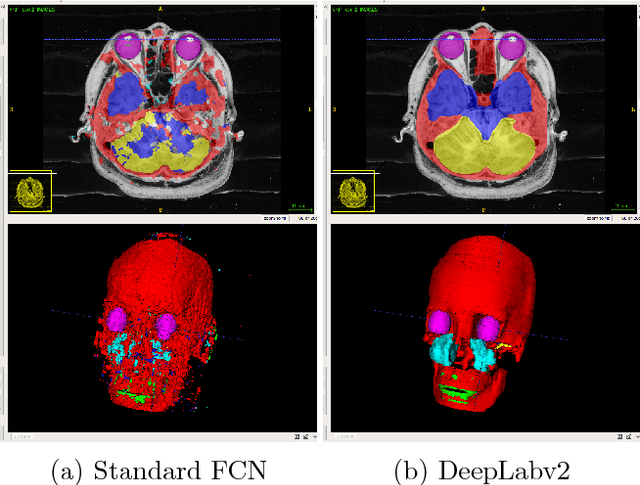
This paper presents an end-to-end pixelwise fully automated segmentation of the head sectioned images of the Visible Korean Human (VKH) project based on Deep Convolutional Neural Networks (DCNNs). By converting classification networks into Fully Convolutional Networks (FCNs), a coarse prediction map, with smaller size than the original input image, can be created for segmentation purposes. To refine this map and to obtain a dense pixel-wise output, standard FCNs use deconvolution layers to upsample the coarse map. However, upsampling based on deconvolution increases the number of network parameters and causes loss of detail because of interpolation. On the other hand, dilated convolution is a new technique introduced recently that attempts to capture multi-scale contextual information without increasing the network parameters while keeping the resolution of the prediction maps high. We used both a standard FCN and a dilated convolution based FCN for semantic segmentation of the head sectioned images of the VKH dataset. Quantitative results showed approximately 20% improvement in the segmentation accuracy when using FCNs with dilated convolutions.