 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of machine learning and deep learning techniques in promoter prediction across diverse species
Paper and Code
May 17, 2021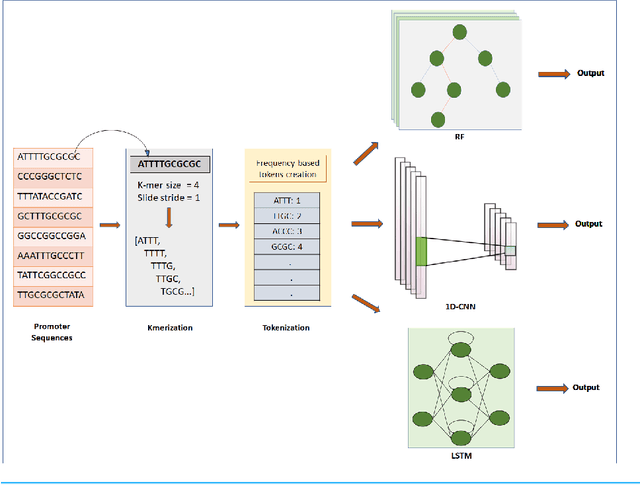

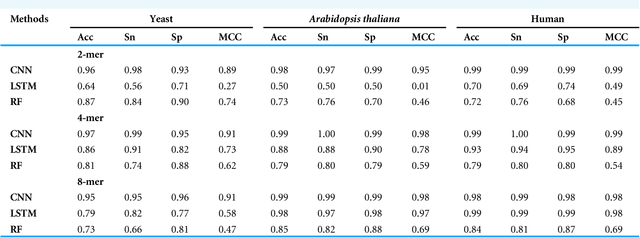

Gene promoters are the key DNA regulatory elements positioned around the transcription start sites and are responsible for regulating gene transcription process. Various alignment-based, signal-based and content-based approaches are reported for the prediction of promoters. However, since all promoter sequences do not show explicit features, the prediction performance of these techniques is poor. Therefore, many machine learning and deep learning models have been proposed for promoter prediction. In this work, we studied methods for vector encoding and promoter classification using genome sequences of three distinct higher eukaryotes viz. yeast (Saccharomyces cerevisiae), A. thaliana (plant) and human (Homo sapiens). We compared one-hot vector encoding method with frequency-based tokenization (FBT) for data pre-processing on 1-D Convolutional Neural Network (CNN) model. We found that FBT gives a shorter input dimension reducing the training time without affecting the sensitivity and specificity of classification. We employed the deep learning techniques, mainly CNN and recurrent neural network with Long Short Term Memory (LSTM) and random forest (RF) classifier for promoter classification at k-mer sizes of 2, 4 and 8. We found CNN to be superior in classification of promoters from non-promoter sequences (binary classification) as well as species-specific classification of promoter sequences (multiclass classification). In summary, the contribution of this work lies in the use of synthetic shuffled negative dataset and frequency-based tokenization for pre-processing. This study provides a comprehensive and generic framework for classification tasks in genomic applications and can be extended to various classification problems.