 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Bayesian predictive methods for model selection
Paper and Code
Mar 23, 2016
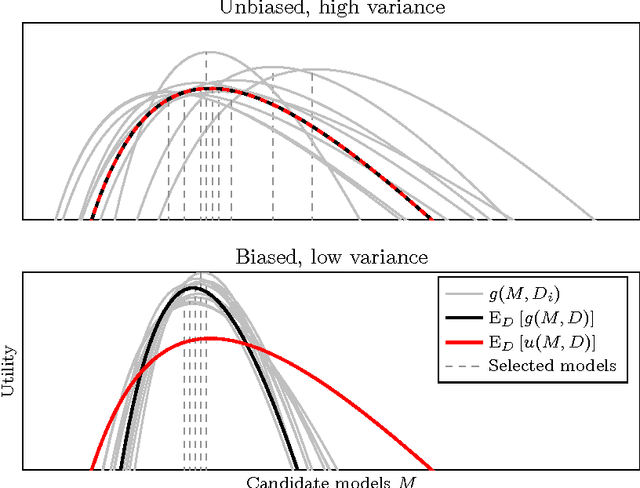

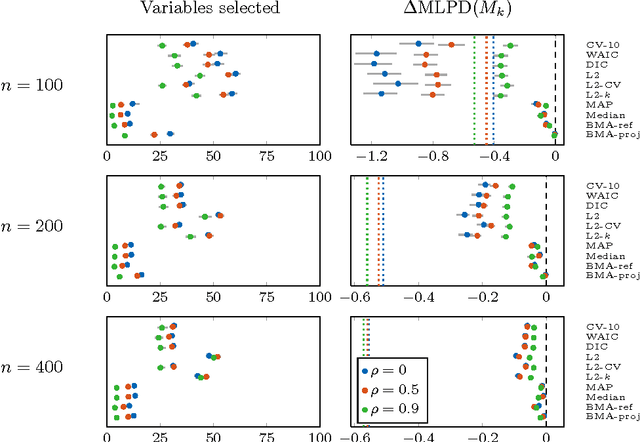
The goal of this paper is to compare several widely used Bayesian model selection methods in practical model selection problems, highlight their differences and give recommendations about the preferred approaches. We focus on the variable subset selection for regression and classification and perform several numerical experiments using both simulated and real world data. The results show that the optimization of a utility estimate such as the cross-validation (CV) score is liable to finding overfitted models due to relatively high variance in the utility estimates when the data is scarce. This can also lead to substantial selection induced bias and optimism in the performance evaluation for the selected model. From a predictive viewpoint, best results are obtained by accounting for model uncertainty by forming the full encompassing model, such as the Bayesian model averaging solution over the candidate models. If the encompassing model is too complex, it can be robustly simplified by the projection method, in which the information of the full model is projected onto the submodels. This approach is substantially less prone to overfitting than selection based on CV-score. Overall, the projection method appears to outperform also the maximum a posteriori model and the selection of the most probable variables. The study also demonstrates that the model selection can greatly benefit from using cross-validation outside the searching process both for guiding the model size selection and assessing the predictive performance of the finally selected model.