 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Targeting Strategies for Maximizing Social Welfare with Limited Resources
Paper and Code
Nov 11, 2024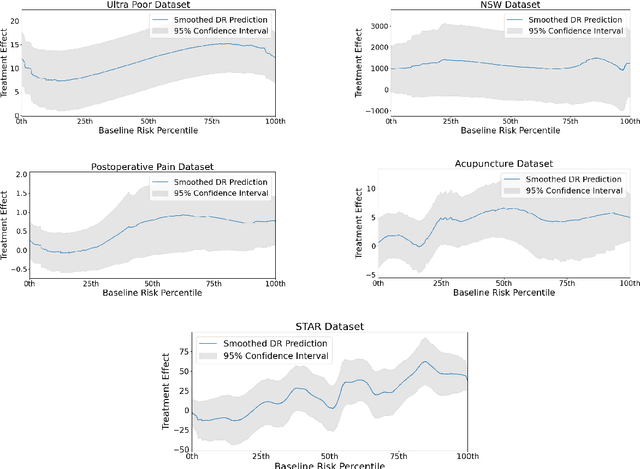
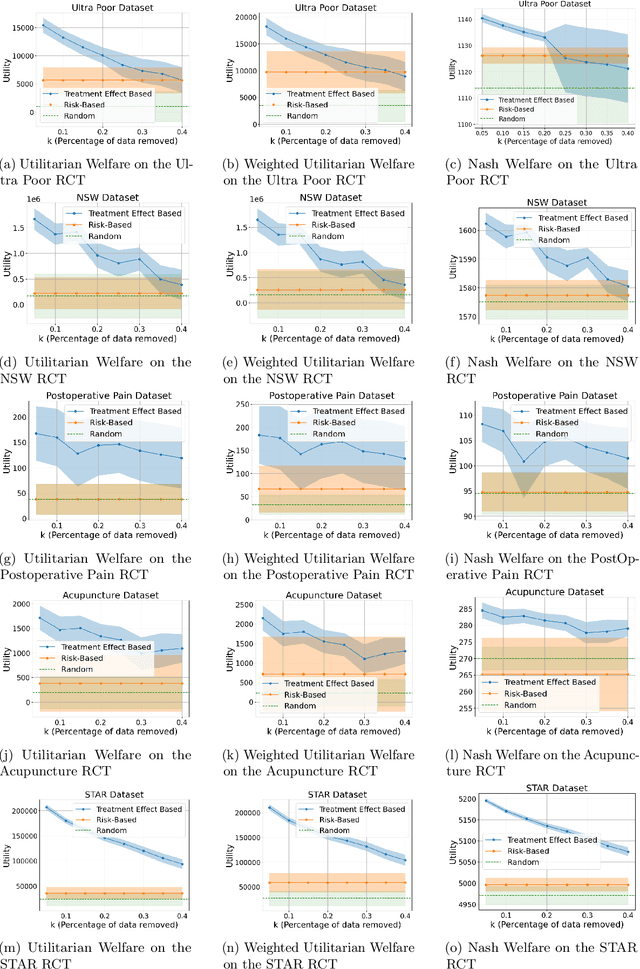
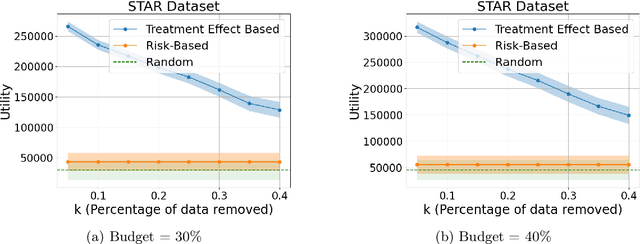
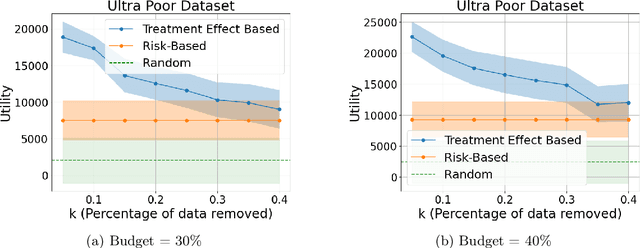
Machine learning is increasingly used to select which individuals receive limited-resource interventions in domains such as human services, education, development, and more. However, it is often not apparent what the right quantity is for models to predict. In particular, policymakers rarely have access to data from a randomized controlled trial (RCT) that would enable accurate estimates of treatment effects -- which individuals would benefit more from the intervention. Observational data is more likely to be available, creating a substantial risk of bias in treatment effect estimates. Practitioners instead commonly use a technique termed "risk-based targeting" where the model is just used to predict each individual's status quo outcome (an easier, non-causal task). Those with higher predicted risk are offered treatment. There is currently almost no empirical evidence to inform which choices lead to the most effect machine learning-informed targeting strategies in social domains. In this work, we use data from 5 real-world RCTs in a variety of domains to empirically assess such choices. We find that risk-based targeting is almost always inferior to targeting based on even biased estimates of treatment effects. Moreover, these results hold even when the policymaker has strong normative preferences for assisting higher-risk individuals. Our results imply that, despite the widespread use of risk prediction models in applied settings, practitioners may be better off incorporating even weak evidence about heterogeneous causal effects to inform targeting.