 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Adam-Type Algorithms for Distributed Data Mining
Paper and Code
Oct 14, 2022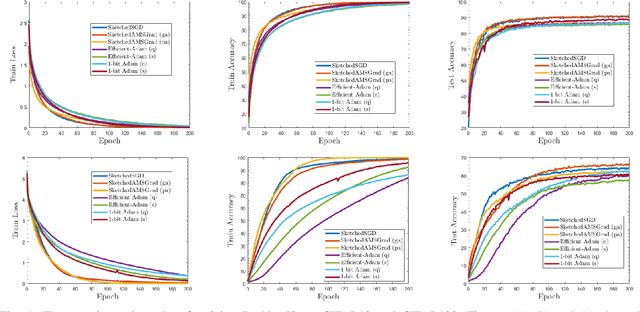
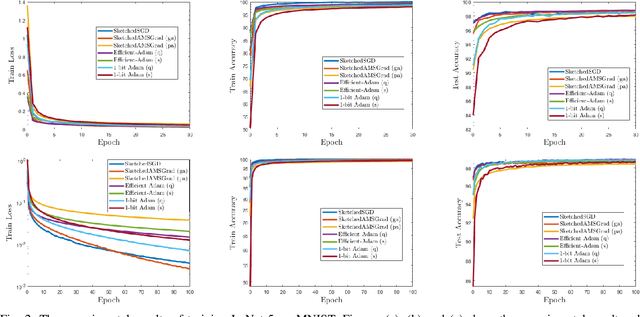

Distributed data mining is an emerging research topic to effectively and efficiently address hard data mining tasks using big data, which are partitioned and computed on different worker nodes, instead of one centralized server. Nevertheless, distributed learning methods often suffer from the communication bottleneck when the network bandwidth is limited or the size of model is large. To solve this critical issue, many gradient compression methods have been proposed recently to reduce the communication cost for multiple optimization algorithms. However, the current applications of gradient compression to adaptive gradient method, which is widely adopted because of its excellent performance to train DNNs, do not achieve the same ideal compression rate or convergence rate as Sketched-SGD. To address this limitation, in this paper, we propose a class of novel distributed Adam-type algorithms (\emph{i.e.}, SketchedAMSGrad) utilizing sketching, which is a promising compression technique that reduces the communication cost from $O(d)$ to $O(\log(d))$ where $d$ is the parameter dimension. In our theoretical analysis, we prove that our new algorithm achieves a fast convergence rate of $O(\frac{1}{\sqrt{nT}} + \frac{1}{(k/d)^2 T})$ with the communication cost of $O(k \log(d))$ at each iteration. Compared with single-machine AMSGrad, our algorithm can achieve the linear speedup with respect to the number of workers $n$. The experimental results on training various DNNs in distributed paradigm validate the efficiency of our algorithms.