 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication and Energy Efficient Federated Learning using Zero-Order Optimization Technique
Paper and Code
Sep 24, 2024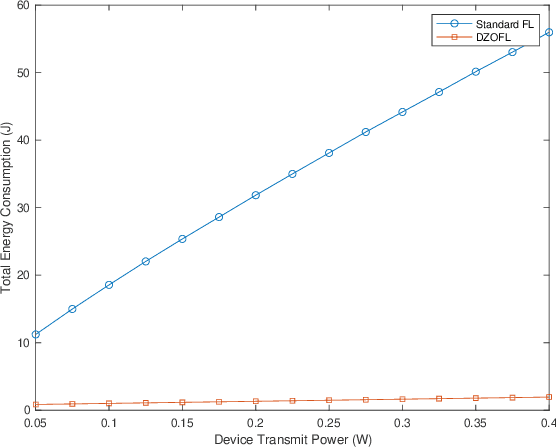
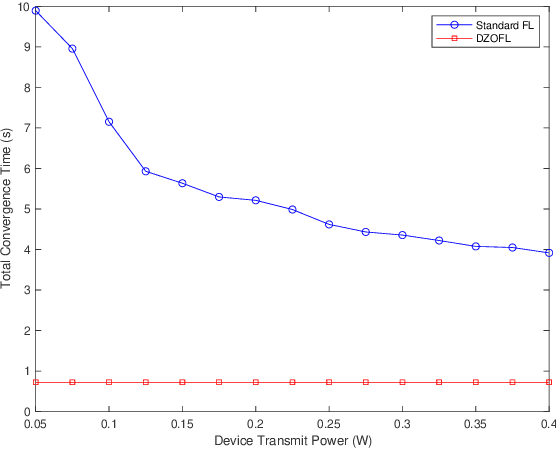
Federated learning (FL) is a popular machine learning technique that enables multiple users to collaboratively train a model while maintaining the user data privacy. A significant challenge in FL is the communication bottleneck in the upload direction, and thus the corresponding energy consumption of the devices, attributed to the increasing size of the model/gradient. In this paper, we address this issue by proposing a zero-order (ZO) optimization method that requires the upload of a quantized single scalar per iteration by each device instead of the whole gradient vector. We prove its theoretical convergence and find an upper bound on its convergence rate in the non-convex setting, and we discuss its implementation in practical scenarios. Our FL method and the corresponding convergence analysis take into account the impact of quantization and packet dropping due to wireless errors. We show also the superiority of our method, in terms of communication overhead and energy consumption, as compared to standard gradient-based FL methods.