Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsense Reasoning Using WordNet and SUMO: a Detailed Analysis
Paper and Code
Sep 06, 2019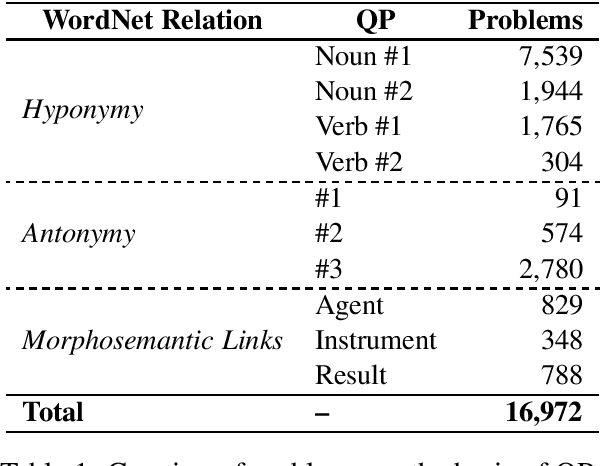
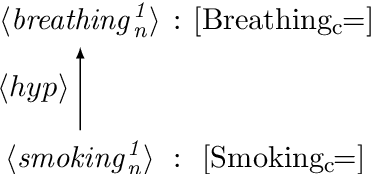
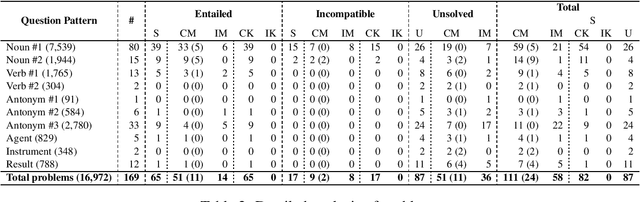
We describe a detailed analysis of a sample of large benchmark of commonsense reasoning problems that has been automatically obtained from WordNet, SUMO and their mapping. The objective is to provide a better assessment of the quality of both the benchmark and the involved knowledge resources for advanced commonsense reasoning tasks. By means of this analysis, we are able to detect some knowledge misalignments, mapping errors and lack of knowledge and resources. Our final objective is the extraction of some guidelines towards a better exploitation of this commonsense knowledge framework by the improvement of the included resources.
* 9 pages, 2 figures, 2 tables; 10th Global WordNet Conference - GWC
2019
View paper on