 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComHapDet: A Spatial Community Detection Algorithm for Haplotype Assembly
Paper and Code
Nov 27, 2019
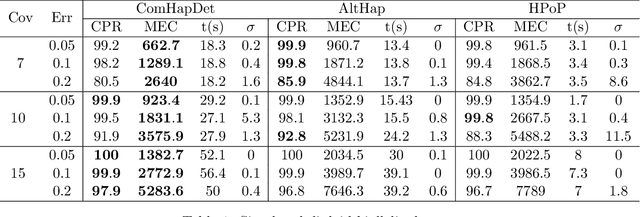

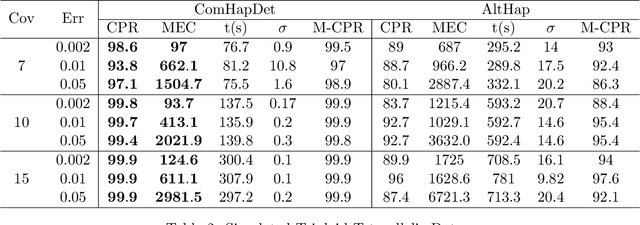
Background: Haplotypes, the ordered lists of single nucleotide variations that distinguish chromosomal sequences from their homologous pairs, may reveal an individual's susceptibility to hereditary and complex diseases and affect how our bodies respond to therapeutic drugs. Reconstructing haplotypes of an individual from short sequencing reads is an NP-hard problem that becomes even more challenging in the case of polyploids. While increasing lengths of sequencing reads and insert sizes {\color{black} helps improve accuracy of reconstruction}, it also exacerbates computational complexity of the haplotype assembly task. This has motivated the pursuit of algorithmic frameworks capable of accurate yet efficient assembly of haplotypes from high-throughput sequencing data. Results: We propose a novel graphical representation of sequencing reads and pose the haplotype assembly problem as an instance of community detection on a spatial random graph. To this end, we construct a graph where each read is a node with an unknown community label associating the read with the haplotype it samples. Haplotype reconstruction can then be thought of as a two-step procedure: first, one recovers the community labels on the nodes (i.e., the reads), and then uses the estimated labels to assemble the haplotypes. Based on this observation, we propose ComHapDet - a novel assembly algorithm for diploid and ployploid haplotypes which allows both bialleleic and multi-allelic variants. Conclusions: Performance of the proposed algorithm is benchmarked on simulated as well as experimental data obtained by sequencing Chromosome $5$ of tetraploid biallelic \emph{Solanum-Tuberosum} (Potato). The results demonstrate the efficacy of the proposed method and that it compares favorably with the existing techniques.