Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining RGB and Points to Predict Grasping Region for Robotic Bin-Picking
Paper and Code
Apr 24, 2019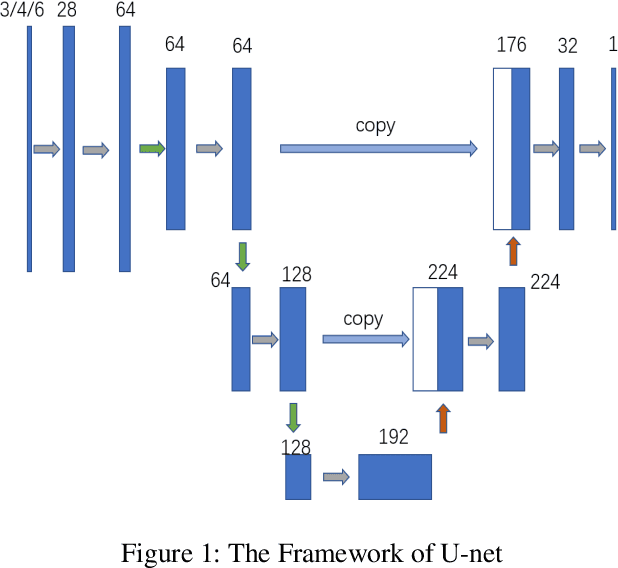
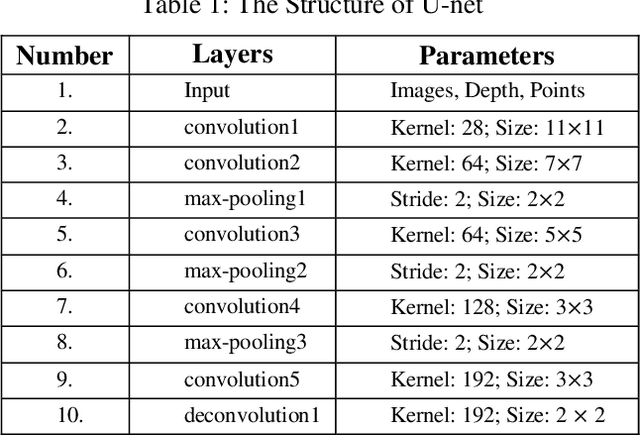


This paper focuses on a robotic picking tasks in cluttered scenario. Because of the diversity of objects and clutter by placing, it is much difficult to recognize and estimate their pose before grasping. Here, we use U-net, a special Convolution Neural Networks (CNN), to combine RGB images and depth information to predict picking region without recognition and pose estimation. The efficiency of diverse visual input of the network were compared, including RGB, RGB-D and RGB-Points. And we found the RGB-Points input could get a precision of 95.74%.
* 5 pages, 6 figures
View paper on