 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombination of Deep Speaker Embeddings for Diarisation
Paper and Code



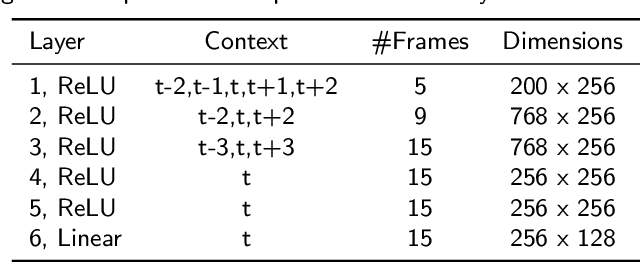
Recently, significant progress has been made in speaker diarisation after the introduction of d-vectors as speaker embeddings extracted from the neural network (NN) speaker classifiers for clustering speech segments. To extract better-performing and more robust speaker embeddings, this paper proposes a c-vector method by combining multiple sets of complementary d-vectors derived from systems with different NN components. Three structures are used to implement the c-vectors, namely 2D self-attentive, gated additive, and bilinear pooling structures, relying on attention mechanisms, a gating mechanism, and a low-rank bilinear pooling mechanism respectively. Furthermore, a neural-based single-pass speaker diarisation pipeline is also proposed in this paper, which uses NNs to achieve voice activity detection, speaker change point detection, and speaker embedding extraction. Experiments and detailed analyses are conducted on the challenging AMI and NIST RT05 datasets which consist of real meetings with 4--10 speakers and a wide range of acoustic conditions. Consistent improvements are obtained by using c-vectors instead of d-vectors, and similar relative improvements in diarisation error rates are observed on both AMI and RT05, which shows the robustness of the proposed methods.