 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLREG-Compliant Collision Avoidance for Unmanned Surface Vehicle using Deep Reinforcement Learning
Paper and Code
Jun 16, 2020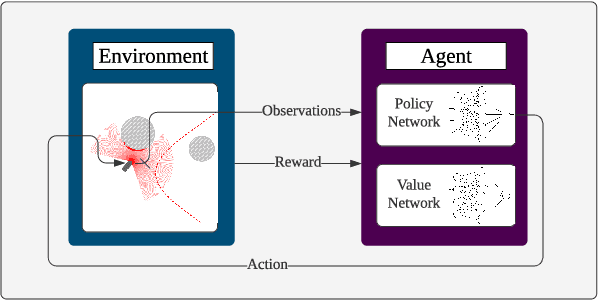

Path Following and Collision Avoidance, be it for unmanned surface vessels or other autonomous vehicles, are two fundamental guidance problems in robotics. For many decades, they have been subject to academic study, leading to a vast number of proposed approaches. However, they have mostly been treated as separate problems, and have typically relied on non-linear first-principles models with parameters that can only be determined experimentally. The rise of Deep Reinforcement Learning (DRL) in recent years suggests an alternative approach: end-to-end learning of the optimal guidance policy from scratch by means of a trial-and-error based approach. In this article, we explore the potential of Proximal Policy Optimization (PPO), a DRL algorithm with demonstrated state-of-the-art performance on Continuous Control tasks, when applied to the dual-objective problem of controlling an underactuated Autonomous Surface Vehicle in a COLREGs compliant manner such that it follows an a priori known desired path while avoiding collisions with other vessels along the way. Based on high-fidelity elevation and AIS tracking data from the Trondheim Fjord, an inlet of the Norwegian sea, we evaluate the trained agent's performance in challenging, dynamic real-world scenarios where the ultimate success of the agent rests upon its ability to navigate non-uniform marine terrain while handling challenging, but realistic vessel encounters.