 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollu-Bench: A Benchmark for Predicting Language Model Hallucinations in Code
Paper and Code
Oct 13, 2024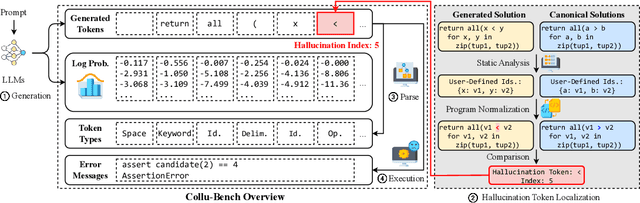
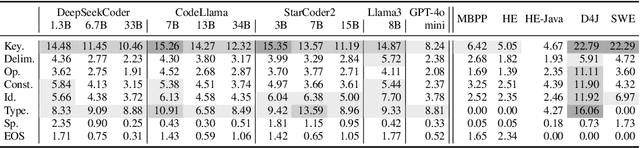


Despite their success, large language models (LLMs) face the critical challenge of hallucinations, generating plausible but incorrect content. While much research has focused on hallucinations in multiple modalities including images and natural language text, less attention has been given to hallucinations in source code, which leads to incorrect and vulnerable code that causes significant financial loss. To pave the way for research in LLMs' hallucinations in code, we introduce Collu-Bench, a benchmark for predicting code hallucinations of LLMs across code generation (CG) and automated program repair (APR) tasks. Collu-Bench includes 13,234 code hallucination instances collected from five datasets and 11 diverse LLMs, ranging from open-source models to commercial ones. To better understand and predict code hallucinations, Collu-Bench provides detailed features such as the per-step log probabilities of LLMs' output, token types, and the execution feedback of LLMs' generated code for in-depth analysis. In addition, we conduct experiments to predict hallucination on Collu-Bench, using both traditional machine learning techniques and neural networks, which achieves 22.03 -- 33.15% accuracy. Our experiments draw insightful findings of code hallucination patterns, reveal the challenge of accurately localizing LLMs' hallucinations, and highlight the need for more sophisticated techniques.