 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLLIDER: A Robust Training Framework for Backdoor Data
Paper and Code
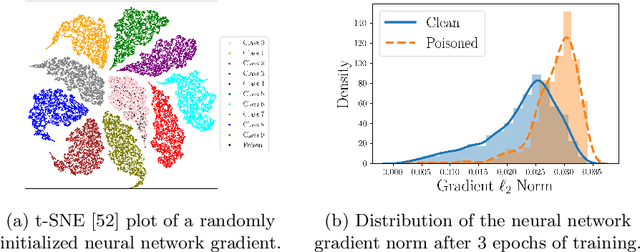
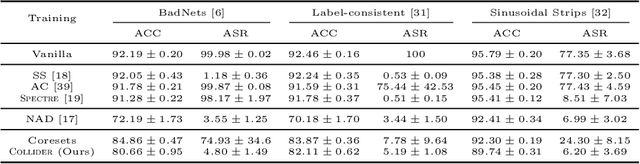
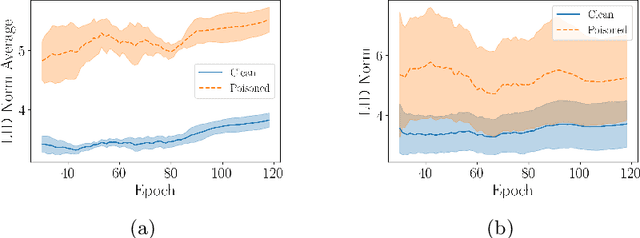
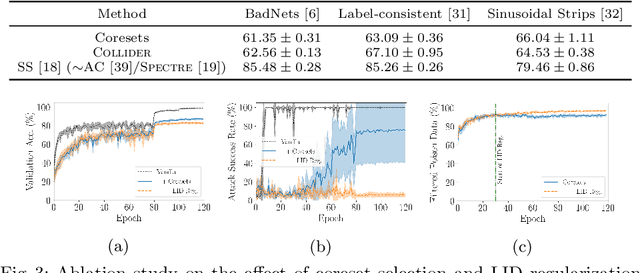
Deep neural network (DNN) classifiers are vulnerable to backdoor attacks. An adversary poisons some of the training data in such attacks by installing a trigger. The goal is to make the trained DNN output the attacker's desired class whenever the trigger is activated while performing as usual for clean data. Various approaches have recently been proposed to detect malicious backdoored DNNs. However, a robust, end-to-end training approach, like adversarial training, is yet to be discovered for backdoor poisoned data. In this paper, we take the first step toward such methods by developing a robust training framework, COLLIDER, that selects the most prominent samples by exploiting the underlying geometric structures of the data. Specifically, we effectively filter out candidate poisoned data at each training epoch by solving a geometrical coreset selection objective. We first argue how clean data samples exhibit (1) gradients similar to the clean majority of data and (2) low local intrinsic dimensionality (LID). Based on these criteria, we define a novel coreset selection objective to find such samples, which are used for training a DNN. We show the effectiveness of the proposed method for robust training of DNNs on various poisoned datasets, reducing the backdoor success rate significantly.