 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Multi-agent Stochastic Linear Bandits
Paper and Code
May 12, 2022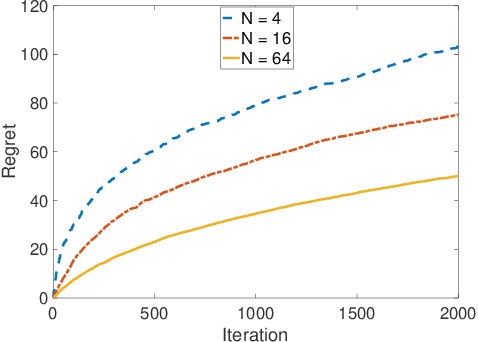
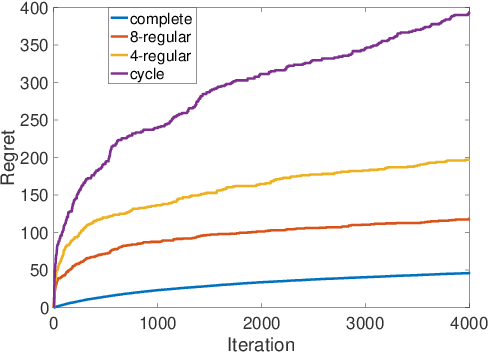
We study a collaborative multi-agent stochastic linear bandit setting, where $N$ agents that form a network communicate locally to minimize their overall regret. In this setting, each agent has its own linear bandit problem (its own reward parameter) and the goal is to select the best global action w.r.t. the average of their reward parameters. At each round, each agent proposes an action, and one action is randomly selected and played as the network action. All the agents observe the corresponding rewards of the played actions and use an accelerated consensus procedure to compute an estimate of the average of the rewards obtained by all the agents. We propose a distributed upper confidence bound (UCB) algorithm and prove a high probability bound on its $T$-round regret in which we include a linear growth of regret associated with each communication round. Our regret bound is of order $\mathcal{O}\Big(\sqrt{\frac{T}{N \log(1/|\lambda_2|)}}\cdot (\log T)^2\Big)$, where $\lambda_2$ is the second largest (in absolute value) eigenvalue of the communication matrix.