 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMGAN: Conformer-based Metric GAN for Speech Enhancement
Paper and Code
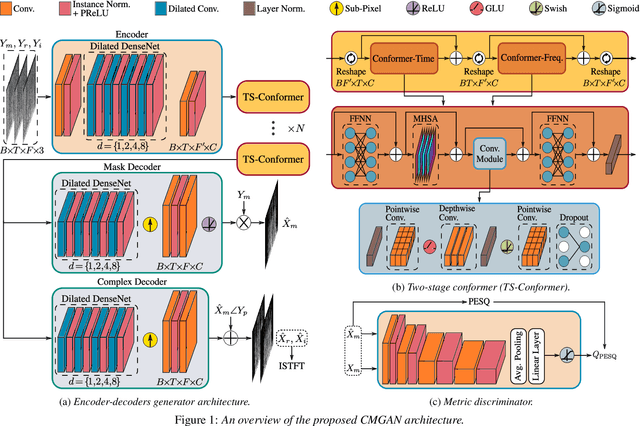
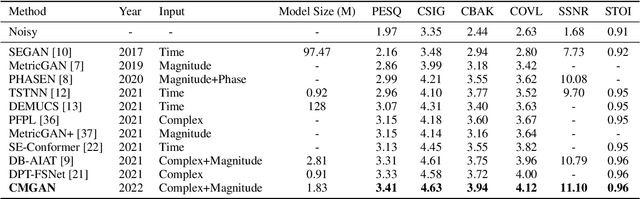
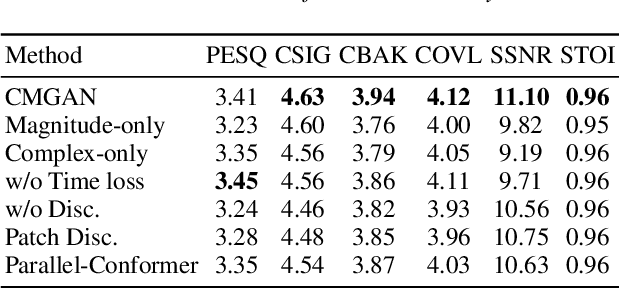
Recently, convolution-augmented transformer (Conformer) has achieved promising performance in automatic speech recognition (ASR) and time-domain speech enhancement (SE), as it can capture both local and global dependencies in the speech signal. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for SE in the time-frequency (TF) domain. In the generator, we utilize two-stage conformer blocks to aggregate all magnitude and complex spectrogram information by modeling both time and frequency dependencies. The estimation of magnitude and complex spectrogram is decoupled in the decoder stage and then jointly incorporated to reconstruct the enhanced speech. In addition, a metric discriminator is employed to further improve the quality of the enhanced estimated speech by optimizing the generator with respect to a corresponding evaluation score. Quantitative analysis on Voice Bank+DEMAND dataset indicates the capability of CMGAN in outperforming various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.