 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMGAN: Conformer-Based Metric-GAN for Monaural Speech Enhancement
Paper and Code
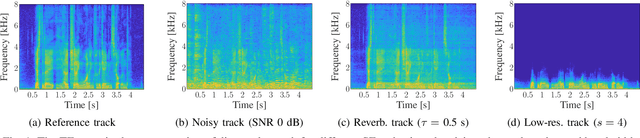
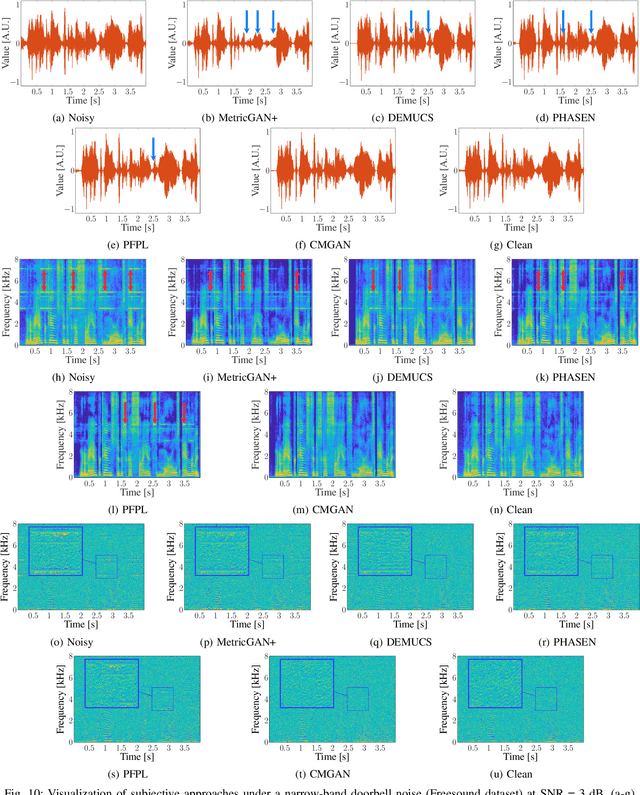
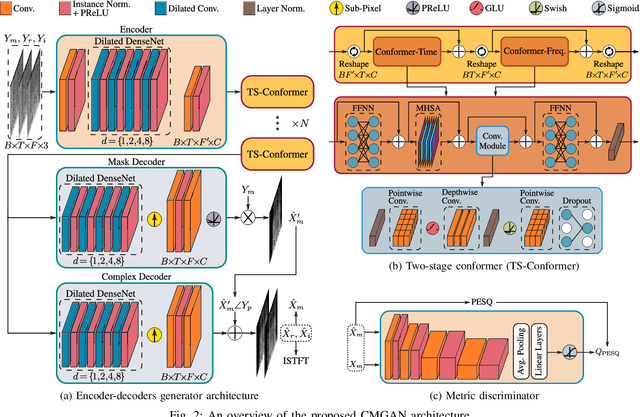
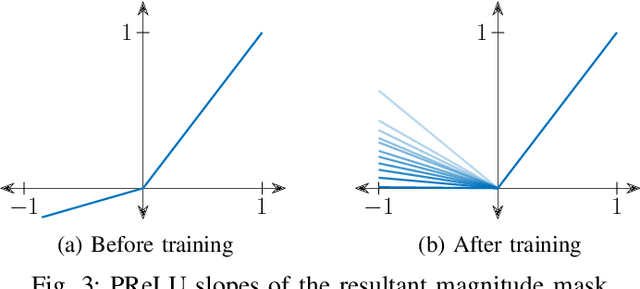
Convolution-augmented transformers (Conformers) are recently proposed in various speech-domain applications, such as automatic speech recognition (ASR) and speech separation, as they can capture both local and global dependencies. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for speech enhancement (SE) in the time-frequency (TF) domain. The generator encodes the magnitude and complex spectrogram information using two-stage conformer blocks to model both time and frequency dependencies. The decoder then decouples the estimation into a magnitude mask decoder branch to filter out unwanted distortions and a complex refinement branch to further improve the magnitude estimation and implicitly enhance the phase information. Additionally, we include a metric discriminator to alleviate metric mismatch by optimizing the generator with respect to a corresponding evaluation score. Objective and subjective evaluations illustrate that CMGAN is able to show superior performance compared to state-of-the-art methods in three speech enhancement tasks (denoising, dereverberation and super-resolution). For instance, quantitative denoising analysis on Voice Bank+DEMAND dataset indicates that CMGAN outperforms various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.