 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Stable Instances of Euclidean k-means
Paper and Code
Dec 04, 2017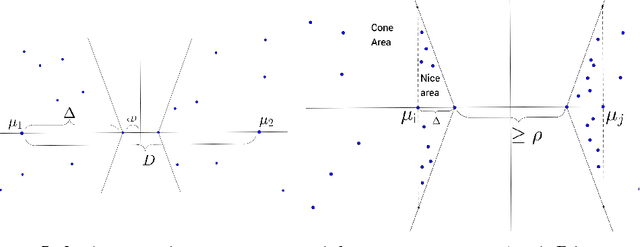
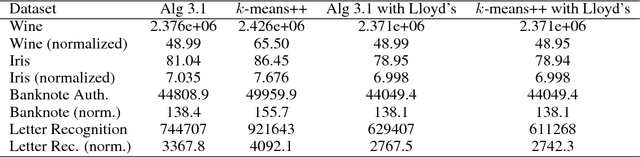
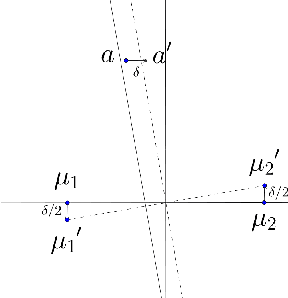
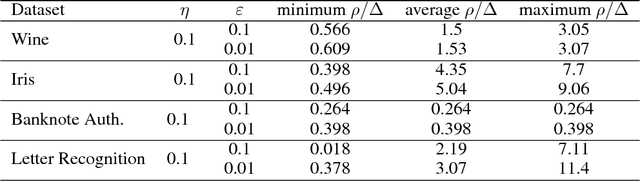
The Euclidean k-means problem is arguably the most widely-studied clustering problem in machine learning. While the k-means objective is NP-hard in the worst-case, practitioners have enjoyed remarkable success in applying heuristics like Lloyd's algorithm for this problem. To address this disconnect, we study the following question: what properties of real-world instances will enable us to design efficient algorithms and prove guarantees for finding the optimal clustering? We consider a natural notion called additive perturbation stability that we believe captures many practical instances. Stable instances have unique optimal k-means solutions that do not change even when each point is perturbed a little (in Euclidean distance). This captures the property that the k-means optimal solution should be tolerant to measurement errors and uncertainty in the points. We design efficient algorithms that provably recover the optimal clustering for instances that are additive perturbation stable. When the instance has some additional separation, we show an efficient algorithm with provable guarantees that is also robust to outliers. We complement these results by studying the amount of stability in real datasets and demonstrating that our algorithm performs well on these benchmark datasets.