 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering small datasets in high-dimension by random projection
Paper and Code
Aug 21, 2020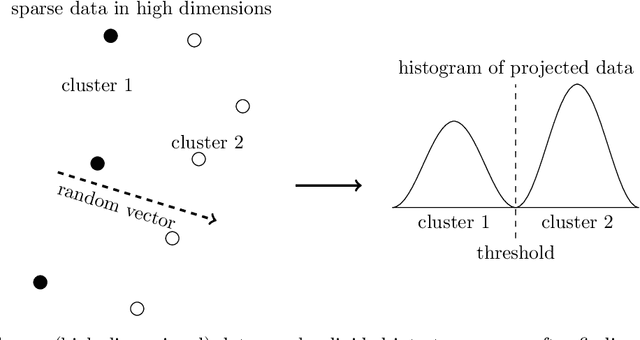
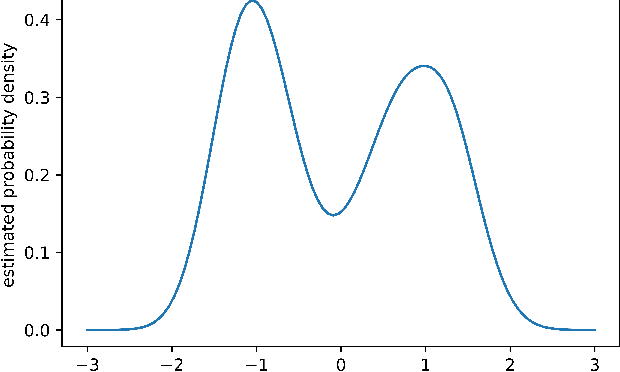
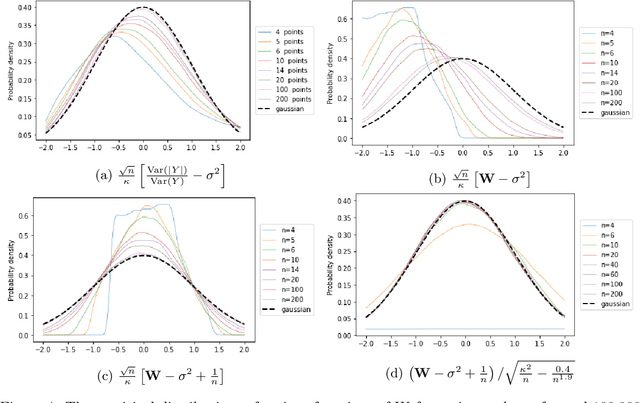
Datasets in high-dimension do not typically form clusters in their original space; the issue is worse when the number of points in the dataset is small. We propose a low-computation method to find statistically significant clustering structures in a small dataset. The method proceeds by projecting the data on a random line and seeking binary clusterings in the resulting one-dimensional data. Non-linear separations are obtained by extending the feature space using monomials of higher degrees in the original features. The statistical validity of the clustering structures obtained is tested in the projected one-dimensional space, thus bypassing the challenge of statistical validation in high-dimension. Projecting on a random line is an extreme dimension reduction technique that has previously been used successfully as part of a hierarchical clustering method for high-dimensional data. Our experiments show that with this simplified framework, statistically significant clustering structures can be found with as few as 100-200 points, depending on the dataset. The different structures uncovered are found to persist as more points are added to the dataset.