 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering by Hierarchical Nearest Neighbor Descent (H-NND)
Paper and Code
Mar 04, 2016
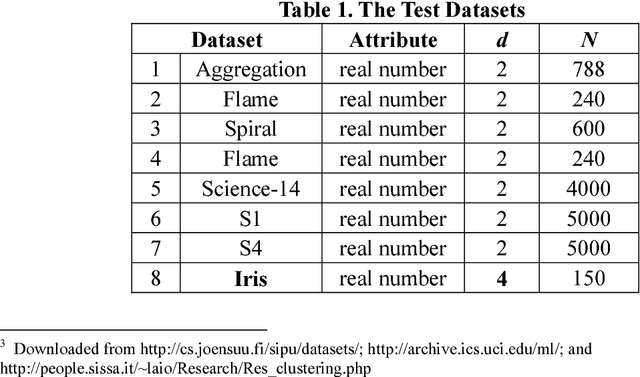
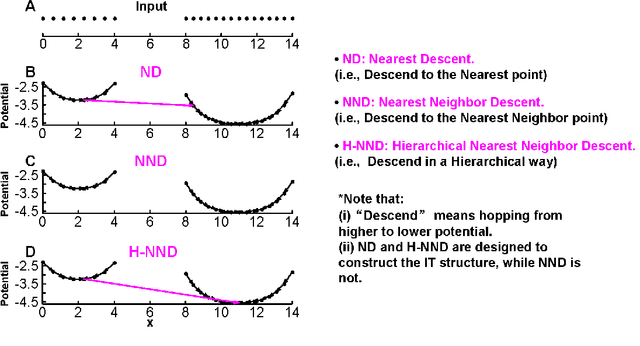
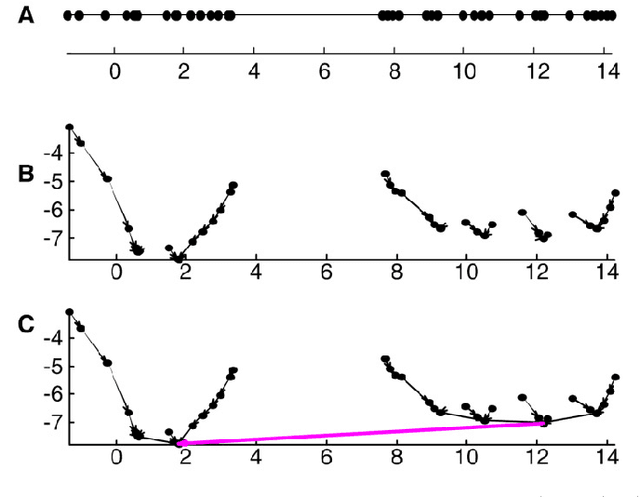
Previously in 2014, we proposed the Nearest Descent (ND) method, capable of generating an efficient Graph, called the in-tree (IT). Due to some beautiful and effective features, this IT structure proves well suited for data clustering. Although there exist some redundant edges in IT, they usually have salient features and thus it is not hard to remove them. Subsequently, in order to prevent the seemingly redundant edges from occurring, we proposed the Nearest Neighbor Descent (NND) by adding the "Neighborhood" constraint on ND. Consequently, clusters automatically emerged, without the additional requirement of removing the redundant edges. However, NND proved still not perfect, since it brought in a new yet worse problem, the "over-partitioning" problem. Now, in this paper, we propose a method, called the Hierarchical Nearest Neighbor Descent (H-NND), which overcomes the over-partitioning problem of NND via using the hierarchical strategy. Specifically, H-NND uses ND to effectively merge the over-segmented sub-graphs or clusters that NND produces. Like ND, H-NND also generates the IT structure, in which the redundant edges once again appear. This seemingly comes back to the situation that ND faces. However, compared with ND, the redundant edges in the IT structure generated by H-NND generally become more salient, thus being much easier and more reliable to be identified even by the simplest edge-removing method which takes the edge length as the only measure. In other words, the IT structure constructed by H-NND becomes more fitted for data clustering. We prove this on several clustering datasets of varying shapes, dimensions and attributes. Besides, compared with ND, H-NND generally takes less computation time to construct the IT data structure for the input data.