 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-RR: Improved CLIP Network for Relation-Focused Cross-Modal Information Retrieval
Paper and Code
Feb 13, 2023

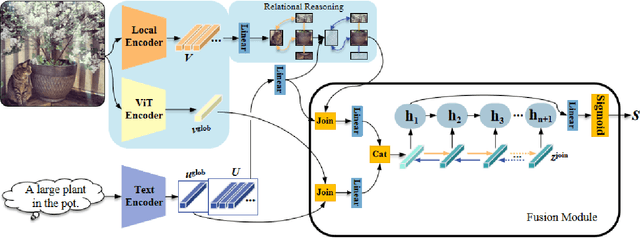

Relation-focused cross-modal information retrieval focuses on retrieving information based on relations expressed in user queries, and it is particularly important in information retrieval applications and next-generation search engines. To date, CLIP (Contrastive Language-Image Pre-training) achieved state-of-the-art performance in cross-modal learning tasks due to its efficient learning of visual concepts from natural language supervision. However, CLIP learns visual representations from natural language at a global level without the capability of focusing on image-object relations. This paper proposes a novel CLIP-based network for Relation Reasoning, CLIP-RR, that tackles relation-focused cross-modal information retrieval. The proposed network utilises CLIP to leverage its pre-trained knowledge, and it additionally comprises two main parts: (1) extends the capabilities of CLIP to extract and reason with object relations in images; and (2) aggregates the reasoned results for predicting the similarity scores between images and descriptions. Experiments were carried out by applying the proposed network to relation-focused cross-modal information retrieval tasks on the RefCOCOg, CLEVR, and Flickr30K datasets. The results revealed that the proposed network outperformed various other state-of-the-art networks including CLIP, VSE$\infty$, and VSRN++ on both image-to-text and text-to-image cross-modal information retrieval tasks.