 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification Under Misspecification: Halfspaces, Generalized Linear Models, and Connections to Evolvability
Paper and Code
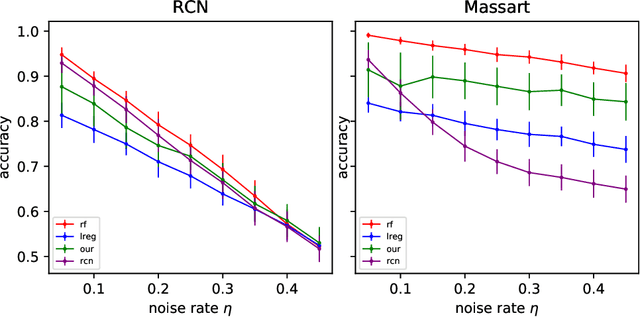
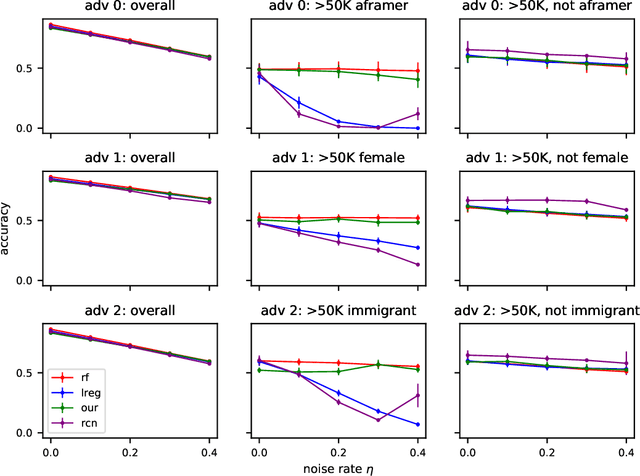
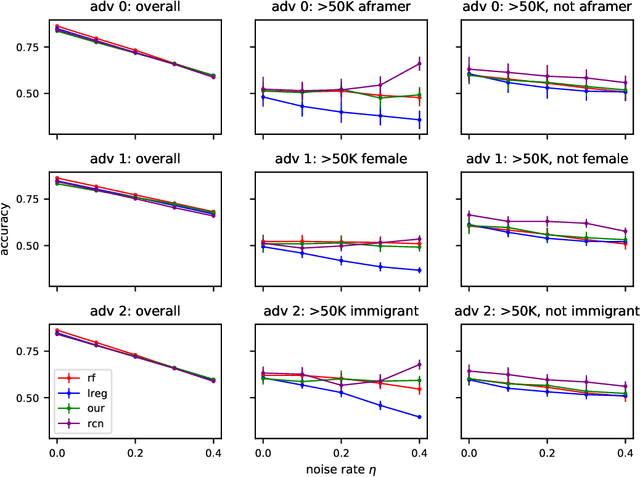
In this paper we revisit some classic problems on classification under misspecification. In particular, we study the problem of learning halfspaces under Massart noise with rate $\eta$. In a recent work, Diakonikolas, Goulekakis, and Tzamos resolved a long-standing problem by giving the first efficient algorithm for learning to accuracy $\eta + \epsilon$ for any $\epsilon > 0$. However, their algorithm outputs a complicated hypothesis, which partitions space into $\text{poly}(d,1/\epsilon)$ regions. Here we give a much simpler algorithm and in the process resolve a number of outstanding open questions: (1) We give the first proper learner for Massart halfspaces that achieves $\eta + \epsilon$. We also give improved bounds on the sample complexity achievable by polynomial time algorithms. (2) Based on (1), we develop a blackbox knowledge distillation procedure to convert an arbitrarily complex classifier to an equally good proper classifier. (3) By leveraging a simple but overlooked connection to evolvability, we show any SQ algorithm requires super-polynomially many queries to achieve $\mathsf{OPT} + \epsilon$. Moreover we study generalized linear models where $\mathbb{E}[Y|\mathbf{X}] = \sigma(\langle \mathbf{w}^*, \mathbf{X}\rangle)$ for any odd, monotone, and Lipschitz function $\sigma$. This family includes the previously mentioned halfspace models as a special case, but is much richer and includes other fundamental models like logistic regression. We introduce a challenging new corruption model that generalizes Massart noise, and give a general algorithm for learning in this setting. Our algorithms are based on a small set of core recipes for learning to classify in the presence of misspecification. Finally we study our algorithm for learning halfspaces under Massart noise empirically and find that it exhibits some appealing fairness properties.