 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification from Ambiguity Comparisons
Paper and Code
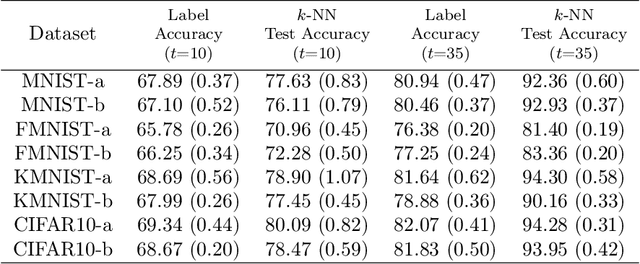
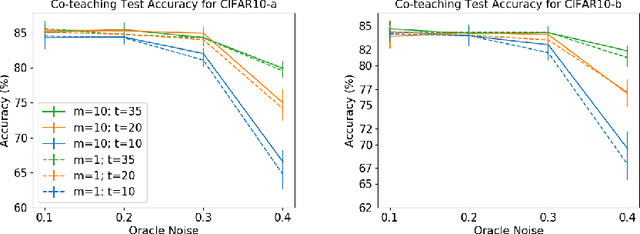
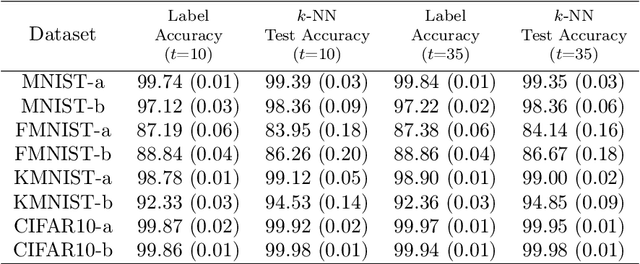
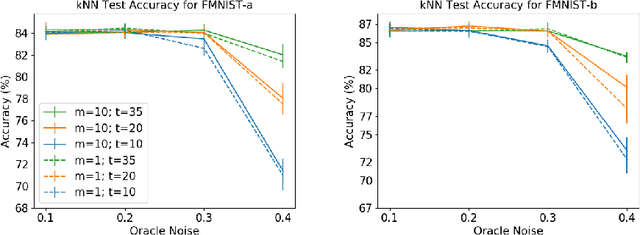
Labeling data is an unavoidable pre-processing procedure for most machine learning tasks. However, it takes a considerable amount of time, money, and labor to collect accurate \textit{explicit class labels} for a large dataset. A positivity comparison oracle has been adapted to relieve this burden, where two data points are received as input and the oracle answers which one is more likely to be positive. However, when information about the classification threshold is lacking, this oracle alone can at most rank all data points on the basis of their relative positivity; thus, it still needs to access explicit class labels. In order to harness pairwise comparisons in a more effective way, we propose an \textit{ambiguity comparison oracle}. This oracle also receives two data points as input, and it answers which one is more ambiguous, or more difficult to assign a label to. We then propose an efficient adaptive labeling algorithm that can actively query \textit{only pairwise comparison oracles} without accessing the explicit labeling oracle. We also address the situation where the labeling budget is insufficient compared to the dataset size, which can be dealt with by plugging the proposed algorithm into an active learning algorithm. Furthermore, we confirm the feasibility of the proposed oracle and the performance of the proposed labeling algorithms theoretically and empirically.