 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification as Direction Recovery: Improved Guarantees via Scale Invariance
Paper and Code
May 17, 2022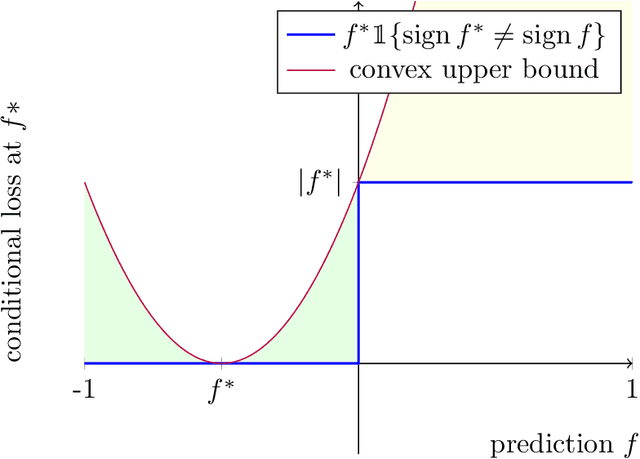

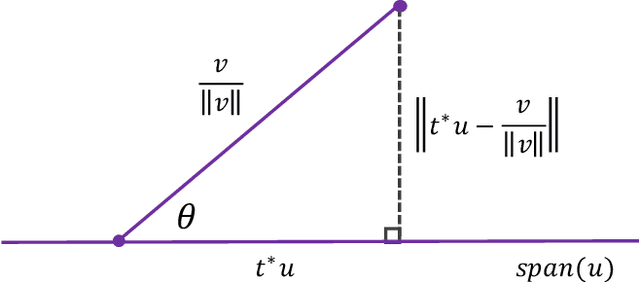
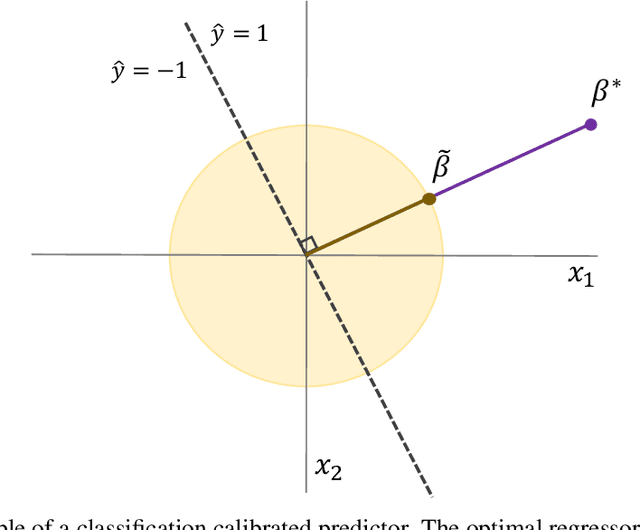
Modern algorithms for binary classification rely on an intermediate regression problem for computational tractability. In this paper, we establish a geometric distinction between classification and regression that allows risk in these two settings to be more precisely related. In particular, we note that classification risk depends only on the direction of the regressor, and we take advantage of this scale invariance to improve existing guarantees for how classification risk is bounded by the risk in the intermediate regression problem. Building on these guarantees, our analysis makes it possible to compare algorithms more accurately against each other and suggests viewing classification as unique from regression rather than a byproduct of it. While regression aims to converge toward the conditional expectation function in location, we propose that classification should instead aim to recover its direction.