 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAMP-ViT: Contrastive Data-Free Learning for Adaptive Post-Training Quantization of ViTs
Paper and Code
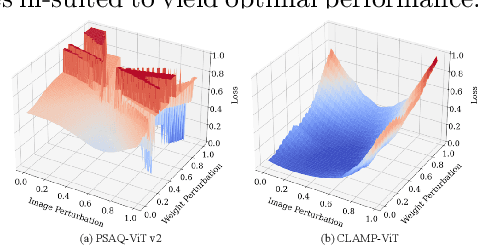

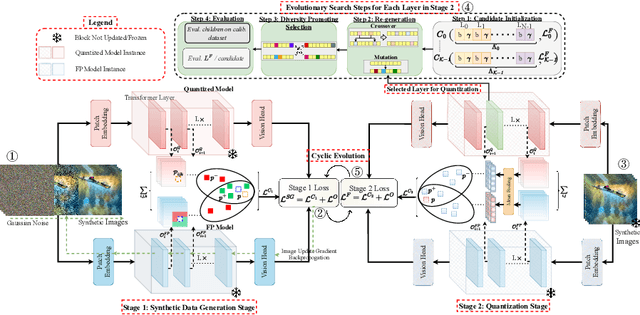

We present CLAMP-ViT, a data-free post-training quantization method for vision transformers (ViTs). We identify the limitations of recent techniques, notably their inability to leverage meaningful inter-patch relationships, leading to the generation of simplistic and semantically vague data, impacting quantization accuracy. CLAMP-ViT employs a two-stage approach, cyclically adapting between data generation and model quantization. Specifically, we incorporate a patch-level contrastive learning scheme to generate richer, semantically meaningful data. Furthermore, we leverage contrastive learning in layer-wise evolutionary search for fixed- and mixed-precision quantization to identify optimal quantization parameters while mitigating the effects of a non-smooth loss landscape. Extensive evaluations across various vision tasks demonstrate the superiority of CLAMP-ViT, with performance improvements of up to 3% in top-1 accuracy for classification, 0.6 mAP for object detection, and 1.5 mIoU for segmentation at similar or better compression ratio over existing alternatives. Code is available at https://github.com/georgia-tech-synergy-lab/CLAMP-ViT.git